Looking back on three years that went into completing our RDM Roadmap in this period of global pandemic and working from home, feels a bit anti-climactic. Nevertheless, the previous three years have been an outstanding period of development for the University’s Research Data Service, and research culture has changed considerably toward openness, with a clearer focus on research integrity. Synergies between ourselves as service providers and researchers seeking RDM support have never been stronger, laying a foundation for potential partnerships in future.

FAIR Roadmap Review Poster
A complete review was written for the service steering group in October last year (available on the RDM wiki to University members). This was followed by a poster and lightning talk prepared for the FAIR Symposium in December where the aspects of the Roadmap that contributed to FAIR principles of research data (findable, accessible, interoperable, reusable) were highlighted.
The Roadmap addressed not only FAIR principles but other high level goals such as interoperability, data protection and information security (both related to GDPR), long-term digital preservation, and research integrity and responsibility. The review examined where we had achieved SMART-style objectives and where we fell short, pointing to gaps either in provision or take-up.
Highlights from the Roadmap Review
The 32 high level objectives, each of which could have more than one deliverable, were categorised into five categories. In terms of Unification of the Service there were a number of early wins, including a professionally produced short video introducing the service to new users; a well-designed brochure serving the same purpose; case study interviews with our researchers also in video format – a product of a local Innovation Grant project; and having our service components well represented in the holistic presentation of the Digital Research Services website.
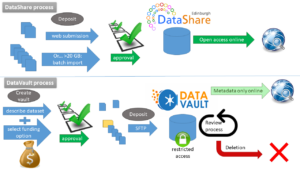
Gaps include the continuing confusion about service components starting with the name ‘Data’___ [Store, Sync, Share, Vault]; the delay of an overarching service level definition covering all components; and the ten-year old Research Data Policy. (The policy is currently being refreshed for consultation – watch this space.)
A number of Data Management Planning goals were in the Roadmap, from increasing uptake, to building capacity for rapid support, to increasing the number of fully costed plans, and ensuring templates in DMPOnline were well tended. This was a mixed success category. Certainly the number of people seeking feedback on plans increased over time and we were able to satisfy all requests and update the University template in DMPOnline. The message on cost recovery in data management plans was amplified by others such as the Research Office and school-based IT support teams, however many research projects are still not passing on RDM costs to the funders as needed.
Not many schools or centres created DMP templates tailored to their own communities yet, with the Roslin Institute being an impressive exception; the large majority of schools still do not mandate a DMP with PhD research proposals, though GeoSciences and the Business School have taken this very seriously. The DMP training our team developed and gave as part of scheduled sessions (now virtually) were well taken up, more by research students than staff. We managed to get software code management into the overall message, as well as the need for data protection impact assessments (DPIAs) for research involving human subjects, though a hurdle is the perceived burden of having to conduct both a DPIA and a DMP for a single research project. A university-wide ethics working group has helped to make linkages to both through approval mechanisms, whilst streamlining approvals with a new tool.
In the category of Working with Active Data, both routine and extraordinary achievements were made, with fewer gaps on stated goals. Infrastructure refreshment has taken place on DataStore, for which cost recovery models have worked well. In some cases institutes have organised hardware purchases through the central service, providing economies of scale. DataSync (OwnCloud) was upgraded. Gitlab was introduced to eventually replace Subversion for code versioning and other aspects of code management. This fit well with Data and Software Carpentry training offered by colleagues within the University to modernise ways of doing coding and cleaning data.
A number of incremental steps toward uptake of electronic notebooks were taken, with RSpace completing its 2-year trial and enterprise subscriptions useful for research groups (not just Labs) being managed by Software Services. Another enterprise tool, protocols.io, was introduced and extended as a trial. EDINA’s Noteable service for Jupyter Notebooks is also showcased.
By far and away the most momentous achievement in this category was bringing into service the University Data Safe Haven to fulfil the innocuous sounding goal of “Provide secure setting for sensitive data and set up controls that meet ISO 27001 compliance and user needs.” An enormous effort from a very small team brought the trusted secure environment for research data to a soft launch at our annual Dealing with Data event in November 2018, with full ISO 27001 standard certification achieved by December 2019. The facility has been approved by a number of external data providers, including NHS bodies. Flexibility has been seen as a primary advantage, with individual builds for each research project, and the ability for projects to define their own ‘gatekeeping’ procedures, depending on their requirements. Achieving complete sustainability on income from research grants however has not proven possible, given the expense and levels of expertise required to run this type of facility. Whether the University is prepared to continue to invest in this facility will likely depend on other options opening up to local researchers such as the new DataLoch, which got its start from government funding in the Edinburgh and South East Scotland region ‘city deal’.
As for gaps in the Working with Data category, there were some expressions of dissatisfaction with pricing models for services offered under cost recovery although our own investigation found them to be competitively priced. We found that researchers working with external partners, especially in countries with different data protection legislation, continue to find it hard work to find easy ways to collaborate with data. Centralised support for databases was never agreed on by the colleges because some already have good local support. Encryption is something that could benefit from a University key management system but researchers are only offered advice and left to their own mechanisms not to lose the keys to their research treasures; the pilot project that colleagues ran in this area was unfortunately not taken forward.
In part 2 of this blog post we will look at the remaining Roadmap categories of Data Stewardship and Research Data Support.
Robin Rice
Data Librarian and Head of Research Data Support
Library and University Collections