In February, Robin Rice and I ventured to Zagreb, Croatia, for the 20th International Digital Curation Conference. This year’s theme was ‘AI, austerity, and authoritarianism: contemporary challenges in digital curation’, which made for a very timely programme of presentations.
In her opening keynote, Dr. Antica Čulina discussed her fascinating research into the reproducibility crisis in Ecology and how Open Research practices can address it.
I attended most of the sessions focused on AI and machine learning, and heard about the different ways digital curators are trying out new applications of these technologies to automate research data management tasks. A popular theme of these sessions was using Large Language Models to fill in missing metadata and to provide automated feedback to researchers writing Data Management Plans. These use cases are both very appealing, but as the outputs of the tools still needed to be checked by human curators every time, the presenters weren’t sure whether these tools were saving or costing time. It was useful to hear different perspectives on creating tools for repository users versus for repository curators, and I’ll follow these projects with great interest. I also enjoyed Michael Groenendyk’s talk on using Large Language Models to detect data citations, which allows institutions to assess the impact of their researchers’ open datasets.
Cassia Smith and myself, beside her award winning poster! Photo by Robin Rice.
The closing keynote featured Dr. Lynda Kellam and Mikala Narlock from the Data Rescue Project, who reflected on the past year they spent preserving access to United States federal data and building a community that cares deeply about the integrity of the US government and its institutions.
DCC put on some excellent social events throughout the conference, including a drinks reception in the Emerald Ballroom at the historic Esplanade Hotel, and dinner and a beer tasting at The Garden Brewery & Taproom. I had so much fun meeting other digital curators from all around the world and sharing experiences and knowledge.
Overall, I highly recommend attending IDCC to anyone who’s interested in current issues in digital curation, and I hope I can go again in the future!
To read more about what went on at IDCC26, you can check out DCC’s summary here:
The following is a guest post by Mick Eadie, Research Information Management Officer at University of Glasgow, on his impressions of Repository Fringe 2017.
From the Arts
The first day afternoon 10×10 (lightning talk) sessions had many of the presentations on Research Data topics. We heard talks about repositories in the arts; evolving research data policy at national and pan-national level; and archival storage and integrations between research data repositories and other systems like Archivematica, EPrints and Pure.
Repositories and their use in managing research data in the arts was kicked off with Nicola Siminson from the Glasgow School of Art with her talk on What RADAR did next: developing a peer review process for research plans. Nicola explained how EPrints has been developed to maximise the value of research data content at GSA by making it more visually appealing and better able to deal with a multitude of non-text based objects and artefacts. She then outlined GSA’s recently developed Annual Research Planning (ARP) tool which is an EPrints add-on that allows the researcher to provide information on their current and planned research activities and potential impact.
GSA have built on this functionality to enable the peer-reviewing of ARPs, which means they can be shared and commented on by others. This has led to significant uptake in the use of the repository by researchers as they are keen to keep their research profile up-to-date, which has in turn raised the repository profile and increased data deposits. There are also likely to be cost-benefits to the institution by using an existing system to help to manage research information as well as outputs, as it keeps content accessible from one place and means the School doesn’t need to procure separate systems.
On Policy
We heard from Martin Donnelly from the DCC on National Open Data and Open Science Policies in Europe. Martin talked about the work done by the DCC and SPARC Europe in assessing policies from across Europe to assess the methodologies used by countries and funders to promote the concept of Open Data across the continent. They found some interesting variants across countries: some funder driven, others more national directives, plans and roadmaps. It was interesting to see how a consensus was emerging around best practice and how the EU through its Horizon 2020 Open Research Data Pilot seemed to be emerging as a driver for increased take up and action.
Storage, Preservation and Integration
No research data day would be complete without discussing archival storage and preservation. Pauline Ward from Edinburgh University gave us an update on Edinburgh DataVault: Local implementation of Jisc DataVault: the value of testing. She highlighted the initial work done at national level by Jisc and the research data Spring project, and went on to discuss the University of Edinburgh’s local version of Data Vault which integrates with their CRIS system (Pure) – allowing a once only upload of the data which links to metadata in the CRIS and creates an archival version of the data. Pauline also hinted at future integration with DropBox which will be interesting to see develop.
Alan Morrison from the University of Strathclyde continued on the systems integration and preservation theme by giving as assessment of Data Management & Preservation using PURE and Archivematica. He gave us the background to Strathclyde’s systems and workflows between Pure and Archivematica, highlighting some interesting challenges in dealing with file-formats in the STEM subjects which are often proprietary and non-standard.
[First published on the DCC Blog, republished here with permission.]
Okay that title is a joke, but an apt one to name a brief reflection of this year’s International Digital Curation Conference in London this week, with the theme of looking ten years back and ten years forward since the UK Digital Curation Centre was founded.
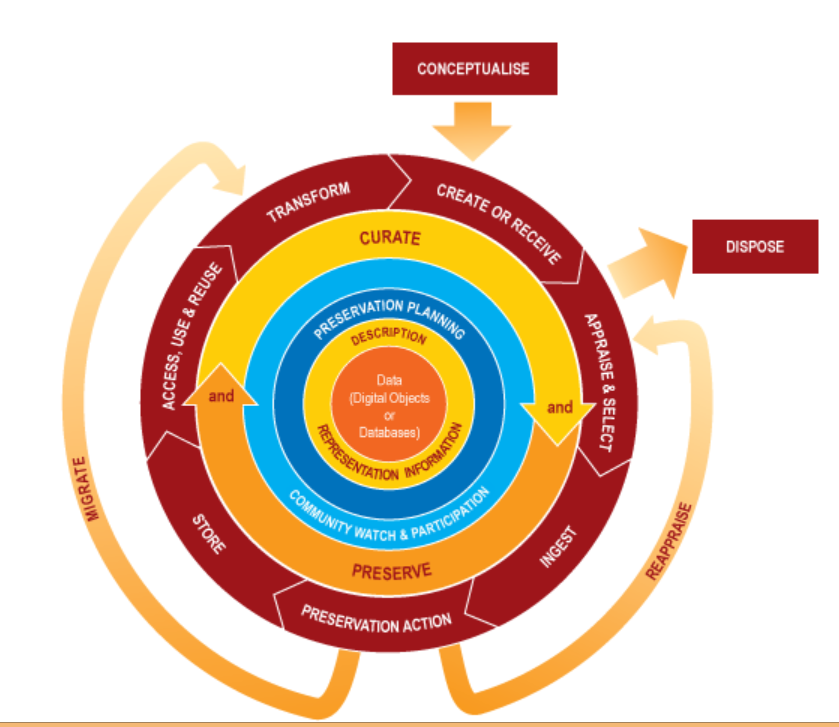
The joke references an alleged written or spoken mistake someone made in referring to the Digital Curation lifecycle model, gleefully repeated on the conference tweetstream (#idcc15). The model itself, as with all great reference works, both builds on prior work and was a product of its time – helping to add to the DCC’s authority within and beyond the UK where people were casting about for common language and understanding in this new terrain of digital preservation, data curation, and – a perplexing combination of terms which perhaps still hasn’t quite taken off, ‘digital curation’ (at least not to the same extent as ‘research data management’). I still have my mouse-mat of the model and live with regrets it was never made into a frisbee.
The Digital Curation Lifecycle Model, Sarah Higgins & DCC, 2008
They say about Woodstock that ‘if you remember it you weren’t really there’, so I don’t feel too bad that it took Tony Hey’s coherent opening plenary talk to remind me of where we started way back in 2004 when a small band under the directorship of Peter Burnhill (services) and Peter Buneman (research) set up the DCC with generous funding from Jisc and EPSRC. Former director Chris Rusbridge likes to talk about ‘standing on the shoulders of giants’ when describing long-term preservation, and Tony reminded us of the important, immediate predecessors of the UK e-Science Programme and the ground-breaking government investment in the Australian National Data Service (ANDS) that was already changing a lot of people’s lifestyles, behaviours and outlooks.
Traditionally the conference has a unique format that focuses on invited panels and talks on the first day, with peer-reviewed research and practice papers on the second, interspersed with demos and posters of cutting edge projects, followed by workshops in the same week. So whilst I always welcome the erudite words of the first day’s contributors, at times there can be a sense of, ‘Wait – haven’t things moved on from there already?’ So it was with the protracted focus on academic libraries and the rallying cries of the need for them to rise to the ‘new’ challenges during the first panel session chaired by Edinburgh’s Geoffrey Boulton, focused ostensibly on international comparisons. Librarians – making up only part of the diverse audience – were asking each other during the break and on twitter, isn’t that exactly what they have been doing in recent years, since for example, the NSF requirements in the States and the RCUK and especially EPSRC rules in the UK, for data management planning and data sharing? Certainly the education and skills of data curators as taught in iSchools (formerly Library Schools) has been a mainstay of IDCC topics in recent years, this one being no exception.
But has anything really changed significantly, either in libraries or more importantly across academia since digital curation entered the namespace a decade ago? This was the focus of a panel led by the proudly impatient Carly Strasser, who has no time for ‘slow’ culture change, and provocatively assumes ‘we’ must be doing something wrong. She may be right, but the panel was divided. Tim DiLauro observed that some disciplines are going fast and some are going slow – depending on whether technology is helping them get the business of research done. And even within disciplines there are vast differences –-perhaps proving the adage that ‘the future is here, it’s just not distributed yet’.
Carly Strasser’s Panel Session, IDCC15
Geoffrey Bilder spoke of tipping points by looking at how recently DOIs (Digital Object Identifiers, used in journal publishing) meant nothing to researchers and how they have since caught on like wildfire. He also pointed blame at the funding system which focuses on short-term projects and forces researchers to disguise their research bids as infrastructure bids – something they rightly don’t care that much about in itself. My own view is that we’re lacking a killer app, probably because it’s not easy to make sustainable and robust digital curation activity affordable and time-rewarding, never mind profitable. (Tim almost said this with his comparison of smartphone adoption). Only time will tell if one of the conference sponsors proves me wrong with its preservation product for institutions, Rosetta.
It took long-time friend of the DCC Clifford Lynch to remind us in the closing summary (day 1) of exactly where it was we wanted to get to, a world of useful, accessible and reproducible research that is efficiently solving humanity’s problems (not his words). Echoing Carly’s question, he admitted bafflement that big changes in scholarly communication always seem to be another five years away, deducing that perhaps the changes won’t be coming from the publishers after all. As ever, he shone a light on sticking points, such as the orthogonal push for human subject data protection, calling for ‘nuanced conversations at scale’ to resolve issues of data availability and access to such datasets.
Perhaps the UK and Scotland in particular are ahead in driving such conversations forward; researchers at the University of Edinburgh co-authored a report two years ago for the government on “Public Acceptability of Data Sharing Between the Public, Private and Third Sectors for Research Purposes,” as a pre-cursor to innovations in providing researchers with secure access to individual National Health Service records linked to other forms of administrative data when informed consent is not possible to achieve.
Given the weight of this societal and moral barrier to data sharing, and the spread of topics over the last 10 years of conferences, I quite agree with Laurence Horton, one of the panelists, who said that the DCC should give a particular focus to the Social Sciences at next year’s conference.
Robin Rice
Data Librarian (and former Project Coordinator, DCC)
University of Edinburgh
[ 1 ] The day started with Prof Tony Kent and his introduction to some of the issues associated with managing and archiving non-text based research outputs. He posed the question: what uses do we expect these outcomes to have in the future? By trying to answer this question, we can think about the information that needs to be preserved with the output and how to preserve both, output and its documentation. He distinguished three common research outcomes in arts-humanities research contexts:
Images. He showed us an image of a research output from a fashion design researcher. The issue with research outputs like this one is that they are not always self explanatory, and quite often open up the question of what is recorded in the image, and what the research outcome actually is. In this case, the image contained information about a new design for a heel of a shoe, but the research outcome itself, the heel, wasn’t easily identifiable, and without further explanation (description metadata), the record would be rendered unusable in the future.
Videos. The example used to explain this type of non-text based research output was a video featuring some of the research of Helen Storey. The video contains information about the project Wonderland and how textiles dissolve in water and water bottles disintegrate. In the video, researchers explain how creativity and materials can be combined to address environmental issues. Videos like this one contain both, records of the research outcome in action (exhibition) and information about what the research outcome is and how the project ideas developed. These are very valuable outcomes, but they contain so much information that it’s difficult to untangle what is the outcome and what is information about the outcome.
Statements. Drawing from his experience, he referred to researchers in fashion and performance arts to explain this research outcome, but I would say it applies to other researchers in humanities and artistic disciplines as well. The issue with these research outcomes is the complexity of the research problems the researchers are addressing and the difficulty of expressing and describing what their research is about, and how the different elements that compose their research project outcomes interact with each other. How much text do we need to understand non-text-based research outcomes such as images and videos? How important is the description of the overall project to understand the different research outcomes?
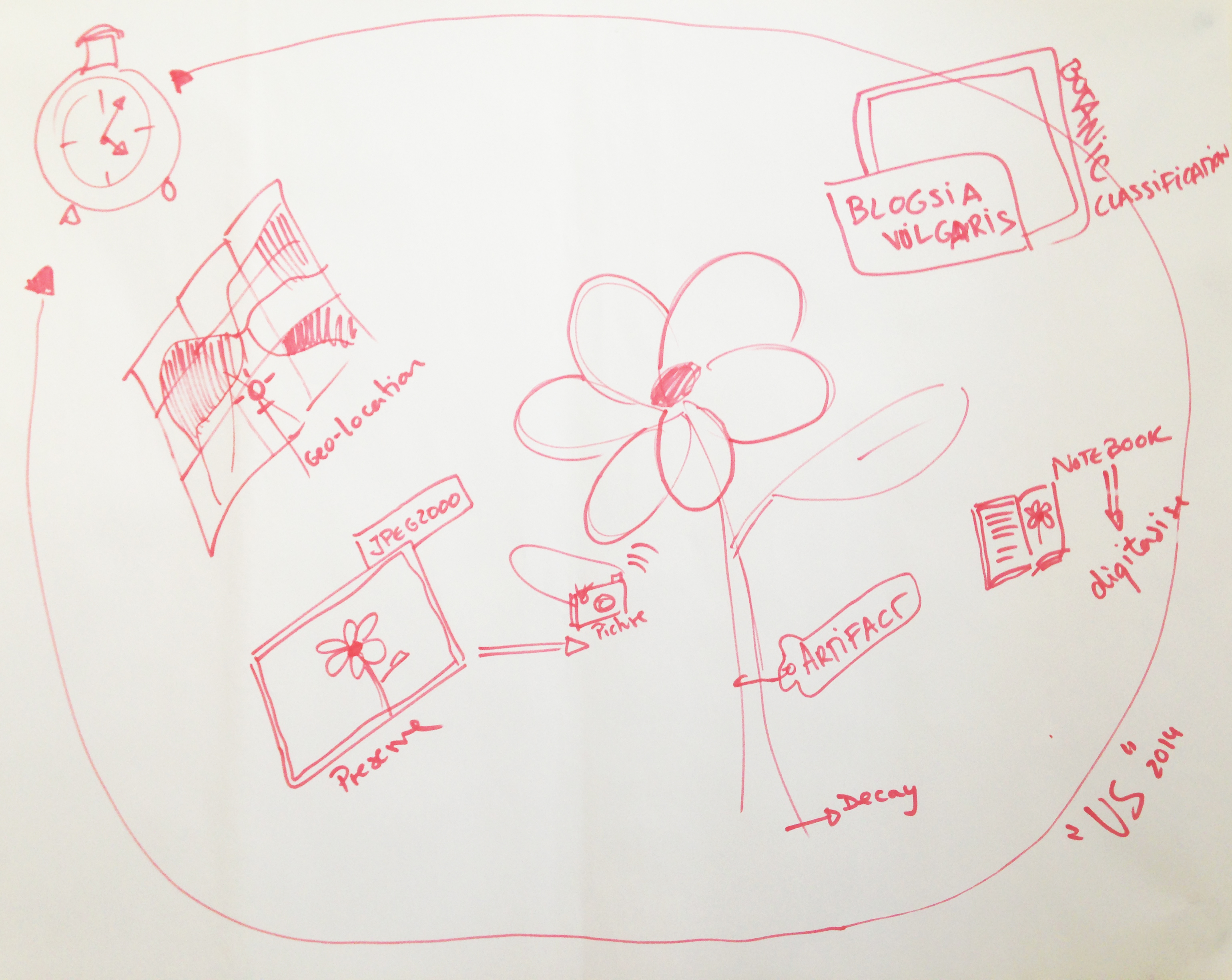
Other questions that come to mind when thinking about collecting and archiving non-standard research outputs such as exhibitions are: ‘what elements of the exhibition do we need to capture? Do we capture the pieces exhibited individually or collectively? How can audio/visual documentation convey the spatial arrangements of these pieces and their interrelations? What exactly constitutes the research outputs? Installation plans, cards, posters, dresses, objects, images, print-outs, visualisations, visitors comments, etc.? We also discussed how to structure data in a repository for artefacts that go into different exhibitions and installations. How to define a practice-based research output that has a life in its own? How do we address this temporal element, the progression and growth of the research output? This flowchart might be useful. Shared with permission of James Toon and collaborators.
Sketch from group discussion about artefacts and research practices that are ephemeral. How to capture the artefact as well as spatial information, notes, context, images, etc.
[ 2 ] After these first insights into the complexity of what non-standard research outcomes are, Stephanie Meece from the University of the Arts London (UAL) discussed her experience as institutional manager of the UAL repository. This repository is for research outputs, but they have also set up another repository for research data which is currently not publicly available. The research output repository has thousands of deposits, but the data repository has ingested only one dataset in its first two months of existence. The dataset in question is related to a media-archaeology research project where a number of analogue-based media (tapes) are being digitised. This reinforced my suspicion that researchers in the arts and humanities are ready and keen to deposit final research outputs, but are less inclined to deposit their core data, the primary sources from which their research outputs derive.
The UAL learned a great deal about non-standard research outputs through the KULTUR project, a Jisc funded project focused on developing repository solutions for the arts. Practice-based research methods engage with theories and practices in a different way than more traditional research methods. In their enquiries about specific metadata for the arts, the KULTUR project identified that metadata fields like ‘collaborators’ were mostly applicable to the arts (see metadata report, p. 25), and that this type of metadata fields differed from ‘data creator’ or ‘co-author.’ Drawing from this, we should certainly reconsider the metadata fields as well as the wording we use in our repositories to accommodate the needs of researchers in the arts.
Other examples of institutional repositories for the arts shown were VADS (University of the Creative Arts) and RADAR (Glasgow School of Art).
[ 3 ] Afterwards, Bekky Randall made a short presentation in which she explained that non-standard research outputs have a much wider variety of formats than standard text-based outputs. She also explained the importance of getting the researchers to do their own deposits, as they are the ones that know the information required for metadata fields. Once researchers find out what is involved in depositing their research, they will be more aware of what is needed, and get involved earlier with research data management (RDM). This might involve researchers depositing throughout the whole research project instead of at the end when they might have forgotten much of the information related to their files. Increasingly, research funders require data management plans, and there are tools to check what they expect researchers to do in terms of publication and sharing. See SHERPA for more information.
[ 4 ] The presentation slot after lunch is always challenging, but Prof Tom Fisher kept us awake with his insights into non-standard research outcomes. In the arts and humanities it’s sometimes difficult to separate insights from the data. He opened up the question of whether archiving research is mainly for Research Excellence Framework (REF) purposes. His point was to delve into the need to disseminate, access and reuse research outputs in the arts beyond REF. He argued that current artistic practice relates more to the present context (contemporary practice-based research) than to the past. In my opinion, arts and humanities always refer to their context but at the same time look back into the past, and are aware they cannot dismiss the presence of the past. For that reason, it seems relevant to archive current research outputs in the arts, because they will be the resources that arts and humanities researchers might want to use in the future.
He spent some time discussing the Journal for Artistic Research (JAR). This journal was designed taking into account the needs of artistic research (practice-based methodologies and research outcomes in a wide range of media), which do not lend themselves to the linearity of text-based research. The journal is peer-review and this process is made as transparent as possible by publishing the peer-reviews along with the article. Here is an example peer-review of an article submitted to JAR by ECA Professor Neil Mulholland.
[ 5 ] Terry Bucknell delivered a quick introduction to figshare. In his presentation he explained the origins of the figshare repository, and how the platform has improved its features to accommodate non-standard research outputs. The platform was originally thought for sharing scientific data, but has expanded its capabilities to appeal to all disciplines. If you have an ORCID account you can now connect it to figshare.
[ 6 ] The last presentation of the day was delivered by Martin Donnellyfrom the Digital Curation Centre (DCC) who gave a refreshing view into data management for the arts. He pointed out the issue of a scientifically-centred understanding of research data management, and that in order to reach the arts and humanities research community, we might need to change the wording, and change the word ‘data’ for ‘stuff’ when referring to creative research outputs. This reminded me of the paper ‘Making Sense: Talking Data Management with Researchers’ by Catharine Ward et al. (2011) and the Data Curation Profiles that Jane Furness, Academic Support Librarian, created after interviewing two researchers at Edinburgh College of Art, available here.
Quoting from his slides “RDM is the active management and appraisal of data over all the lifecycle of scholarly research.” In the past, data in the sciences was not curated or taken care of after the publication of articles; now this process has changed and most science researchers already actively manage their data throughout the research project. This could be extended to arts and humanities research. Why wait to do it at the end?
The main argument for RDM and data sharing is transparency. The data is available for scrutiny and replication of findings. Sharing is most important when events cannot be replicated, such as performance or a census survey. In the scientific context ‘data’ stands for evidence, but in the arts and humanities this does not apply in the same way. He then referred to the work of Leigh Garrett, and how data gets reused in the arts. Researchers in the arts reuse research outputs but there is the fear of fraud, because some people might not acknowledge the data sources from which their work derives. To avoid this, there is the tendency to have longer embargoes in humanities and arts than in sciences.
After Martin’s presentation, we called it a day. While, waiting for my train at Nottingham Station, I noticed I had forgotten my phone (and the flower sketch picture with it), but luckily Prof Tony Kent came to my rescue, and brought the phone to the station. Thanks to Tony and Off-Peak train tickets, I was able to travel back home on the day.


 From the Arts
From the Arts