Warning: Undefined array key "file" in /apps/www/wordpress/blogs/wp-includes/media.php on line 1686
[Reposted from https://libraryblogs.is.ed.ac.uk/blog/2013/12/20/thinking-about-a-data-vault/]
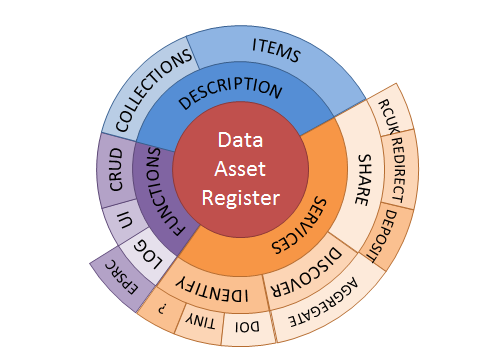
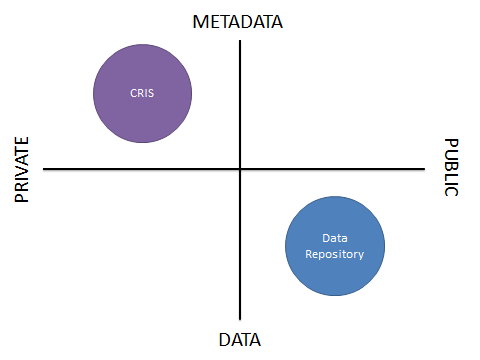
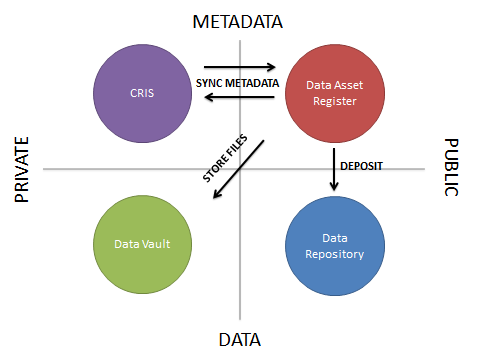
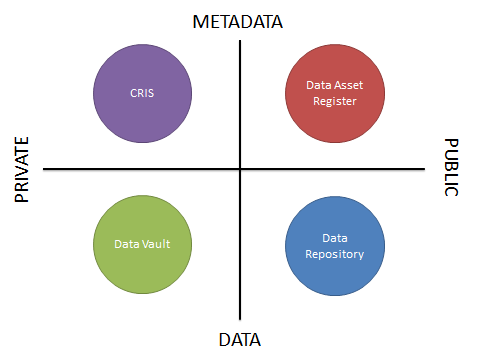
In a recent blog post, we looked at the four quadrants of research data curation systems. This categorised systems that manage or describe research data assets by whether their primary role is to store metadata or data, and whether the information is for private or public use. Four systems were then put into these quadrants. We then started to investigate further the requirements of a Data Asset Register in another blog post.
This blog post will look at the requirements and characteristics of a Data Vault, and how this component fits into the data curation system landscape.
What?
The first aspect to consider is what exactly is a Data Vault? For the purposes of this blog post, we’ll simply consider it is a safe, private, store of data that is only accessible by the data creator or their representative. For simplicity, it could be considered very similar to a safety deposit box within a bank vault. However other than the concept, this analogy starts to break down quite quickly, as we’ll discuss later.
Why?
There are different use cases where a Data Vault would be useful. A few are described here:
- A paper has been published, and according to the research funder’s rules, the data underlying the paper must be made available upon request. It is therefore important to store a date-stamped golden-copy of the data associated with the paper. Even if the author’s own copy of the data is subsequently modified, the data at the point of publication is still available.
- Data containing personal information, perhaps medical records, needs to be stored securely, however the data is ‘complete’ and unlikely to change, yet hasn’t reached the point where it should be deleted.
- Data analysis of a data set has been completed, and the research finished. The data may need to be accessed again, but is unlikely to change, so needn’t be stored in the researcher’s active data store. An example might be a set of completed crystallography analyses, which whilst still useful, will not need to be re-analysed.
- Data is subject to retention rules and must be kept securely for a given period of time.
How?
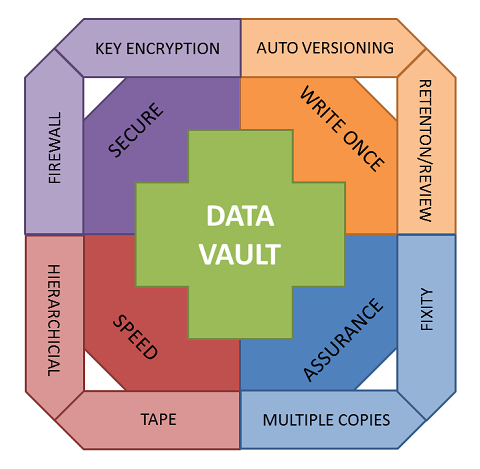
Clearly the storage characteristics for a Data Vault are different to an open data repository or active data filestore for working data. The following is a list of some of the characteristics a Data Vault will need, or could use:
- Write-once file system: The file system should only allow each file to be written once. Deleting a file should require extra effort so that it is hard to remove files.
- Versioning: If the same file needs to be stored again, then rather than overwriting the existing file, it should be stored alongside the file as a new version. This should be an automatic function.
- File security: Only the data owner or their delegate can access the data.
- Storage security: The Data Vault should only be accessible through the local university network, not the wider Internet. This reduces the vectors of attack, which is important given the potential sensitivity of the data contained within the Data Vault.
- Additional security: Encrypt the data, either via key management by the depositors, or within the storage system itself?
- Upload and access: Options include via a web interface (issues with very large files), special shared folders, dedicated upload facilities (e.g. GridFTP), or an API for integration with automated workflows.
- Integration: How would the Data Vault integrate with the Data Asset Register? Could the register be the main user interface for accessing the Data Vault?
- Description: What level of description, or metadata, is required for data sets stored in the Data Vault, to ensure that they can be found and understood in the future?
- Assurance: Facilities to ensure that the file uploaded by the researcher is intact and correct when it reaches the vault, and periodic checks to ensure that the file has not become corrupted. What about more active preservation functions, including file format migration to keep files up to date (e.g. convert Word 95 documents to Word 2013 format)?
- Speed: Can the file system be much slower, perhaps a Hierarchical Storage Management (HSM) system that stores frequently accessed data on disk, but relegates older or less frequently accessed data to slower storage mechanisms such as tape? Access might then be slow (it takes a few minutes for the data to be automatically retrieved from the tape) but the cost of the service is much lower.
- Allocation: How much allocation should each person be given, or should it be unrestricted so as to encourage use? What about costing for additional space? Costings may be hard, because if the data is to be kept for perpetuity, then whole-life costing will be needed. If allocation is free, how to stop it being used for routine backups of data rather than golden-copy data?
- Who: Who is allowed access to the Data Vault to store data?
- Review periods: How to remind data owners what data they have in the Data Vault so that they can review their holdings, and remove unneeded data?
Feedback on these issues and discussion points are very welcome! We will keep this blog updated with further updates as these services develop.
Image available from http://dx.doi.org/10.6084/m9.figshare.873617
Tony Weir, Head of Unix Section, IT Infrastructure
Stuart Lewis, Head of Research and Learning Services, Library & University Collections.