[Guest post from Angus Whyte, Digital Curation Centre]
In the first week of March the 7th Plenary session of the Research Data Alliance got underway in Tokyo. Plenary sessions are the fulcrum of RDA activity, when its many Working Groups and Interest Groups try to get as much leverage as they can out of the previous 6 months of voluntary activity, which is usually coordinated through crackly conference calls.
The Digital Curation Centre (DCC) and others in Edinburgh contribute to a few of these groups, one being the Working Group (WG) on Publishing Data Workflows. Like all such groups it has a fixed time span and agreed deliverables. This WG completes its run at the Tokyo plenary, so there’s no better time to reflect on why DCC has been involved in it, how we’ve worked with others in Edinburgh and what outcomes it’s had.
DCC takes an active part in groups where we see a direct mutual benefit, for example by finding content for our guidance publications. In this case we have a How-to guide planned on ‘workflows for data preservation and publication’. The Publishing Data Workflows WG has taken some initial steps towards a reference model for data publishing, so it has been a great opportunity to track the emerging consensus on best practice, not to mention examples we can use.
One of those examples was close to hand, and DataShare’s workflow and checklist for deposit is identified in the report alongside workflows from other participating repositories and data centres. That report is now available on Zenodo. [1]
In our mini-case studies, the WG found no hard and fast boundaries between ‘data publishing’ and what any repository does when making data publicly accessible. It’s rather a question of how much additional linking and contextualisation is in place to increase data visibility, assure the data quality, and facilitate its reuse. Here’s the working definition we settled on in that report:
Research data publishing is the release of research data, associated metadata, accompanying documentation, and software code (in cases where the raw data have been processed or manipulated) for re-use and analysis in such a manner that they can be discovered on the Web and referred to in a unique and persistent way.
The ‘key components’ of data publishing are illustrated in this diagram produced by Claire C. Austin.
![Data publishing components. Source: Claire C. Austin et al [1]](https://libraryblogs.is.ed.ac.uk/datablog/files/2016/03/Data_publishing_components_Claire_C_Austin-300x137.png)
Data publishing components. Source: Claire C. Austin et al [1]
As the Figure implies, a variety of workflows are needed to build and join up the components. They include those ‘upstream’ around the data collection and analysis, ‘midstream’ workflows around data deposit, packaging and ingest to a repository, and ‘downstream’ to link to other systems. These downstream links could be to third-party preservation systems, publisher platforms, metadata harvesting and citation tracking systems.
The WG recently began some follow-up work to our report that looks ‘upstream’ to consider how the intent to publish data is changing research workflows. Links to third-party systems can also be relevant in these upstream workflows. It has long been an ambition of RDM to capture as much as possible of the metadata and context, as early and as easily as possible. That has been referred to variously as ‘sheer curation’ [2], and ‘publication at source [3]). So we gathered further examples, aiming to illustrate some of the ways that repositories are connecting with these upstream workflows.
Electronic lab notebooks (ELN) can offer one route towards fly-on-the-wall recording of the research process, so the collaboration between Research Space and University of Edinburgh is very relevant to the WG. As noted previously on these pages [4] ,[5], the RSpace ELN has been integrated with DataShare so researchers can deposit directly into it. So we appreciated the contribution Rory Macneil (Research Space) and Pauline Ward (UoE Data Library) made to describe that workflow, one of around half a dozen gathered at the end of the year.
The examples the WG collected each show how one or more of the recommendations in our report can be implemented. There are 5 of these short and to the point recommendations:
- Start small, building modular, open source and shareable components
- Implement core components of the reference model according to the needs of the stakeholder
- Follow standards that facilitate interoperability and permit extensions
- Facilitate data citation, e.g. through use of digital object PIDs, data/article linkages, researcher PIDs
- Document roles, workflows and services
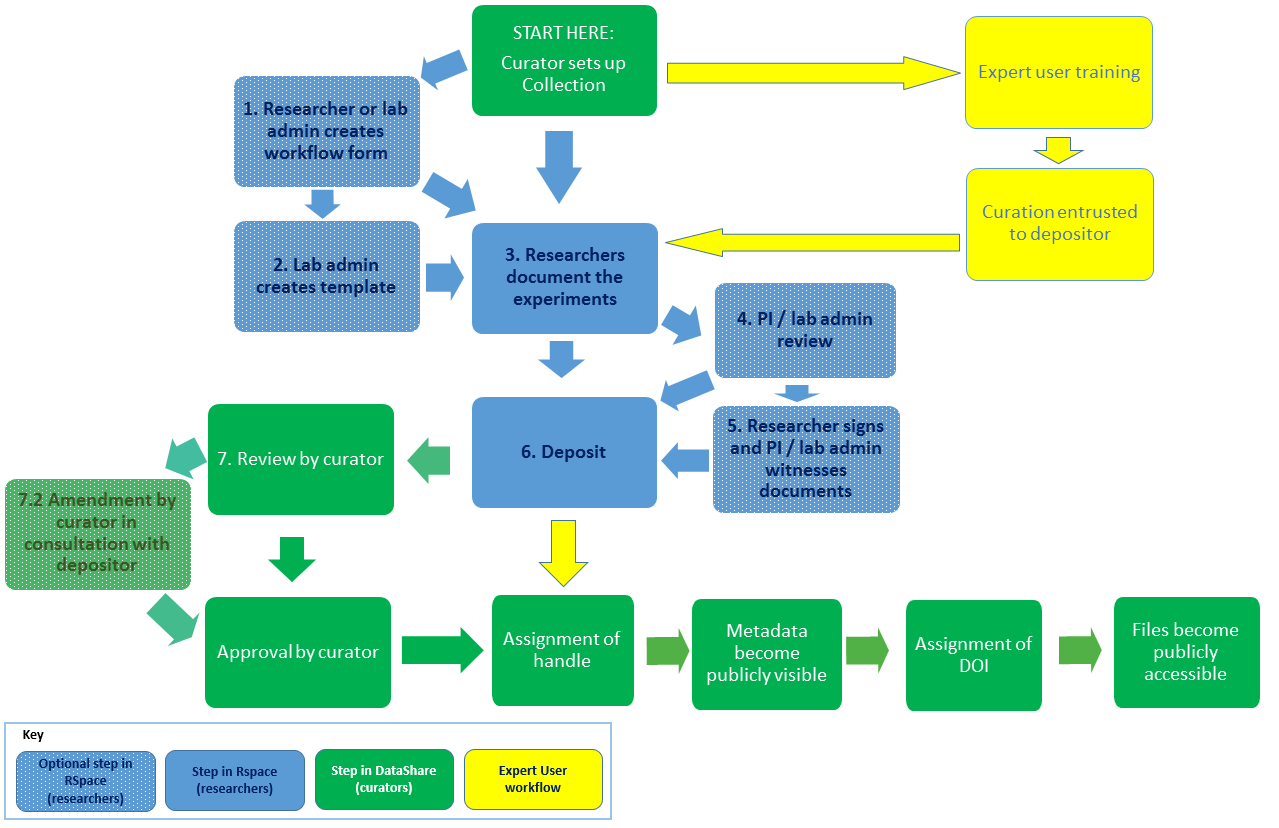
The RSpace-DataShare integration example illustrates how institutions can follow these recommendations by collaborating with partners. RSpace is not open source, but the collaboration does use open standards that facilitate interoperability, namely METS and SWORD, to package up lab books and deposit them for open data sharing. DataShare facilitates data citation, and the workflows for depositing from RSpace are documented, based on DataShare’s existing checklist for depositors. The workflow integrating RSpace with DataShare is shown below:
RSpace-DataShare Workflows
For me one of the most interesting things about this example was learning about the delegation of trust to research groups that can result. If the DataShare curation team can identify an expert user who is planning a large number of data deposits over a period of time, and train them to apply DataShare’s curation standards themselves they would be given administrative rights over the relevant Collection in the database, and the curation step would be entrusted to them for the relevant Collection.
As more researchers take up the challenges of data sharing and reuse, institutional data repositories will need to make depositing as straightforward as they can. Delegating responsibilities and the tools to fulfil them has to be the way to go.
[1] Austin, C et al.. (2015). Key components of data publishing: Using current best practices to develop a reference model for data publishing. Available at: http://dx.doi.org/10.5281/zenodo.34542
[2] ‘Sheer Curation’ Wikipedia entry. Available at: https://en.wikipedia.org/wiki/Digital_curation#.22Sheer_curation.22
[3] Frey, J. et al (2015) Collection, Curation, Citation at Source: Publication@Source 10 Years On. International Journal of Digital Curation. 2015, Vol. 10, No. 2, pp. 1-11
http://doi:10.2218/ijdc.v10i2.377
[4] Macneil, R. (2014) Using an Electronic Lab Notebook to Deposit Data https://libraryblogs.is.ed.ac.uk/2014/04/15/using-an-electronic-lab-notebook-to-deposit-data/
[5] Macdonald, S. and Macneil, R. Service Integration to Enhance Research Data Management: RSpace Electronic Laboratory Notebook Case Study International Journal of Digital Curation 2015, Vol. 10, No. 1, pp. 163-172. http://doi:10.2218/ijdc.v10i1.354
Angus Whyte is a Senior Institutional Support Officer at the Digital Curation Centre.


![Data publishing components. Source: Claire C. Austin et al [1]](https://libraryblogs.is.ed.ac.uk/datablog/files/2016/03/Data_publishing_components_Claire_C_Austin.png)