Ever wanted to get a table of the details of all the datasets on DataShare to do with Scottish history? Or matching some other criteria, possibly on specified fields? If so, the new API (Application Programming Interface) can help.
DataShare now has a REST API, which you can use to query our metadata. An API makes the database’s contents accessible for requests from external servers, through a command-line, which allows external users to script such requests. The DSpace API also provides its own web-based query client and report client. These pages allow users to use a graphical interface to quickly build a query and see the results in a table, all in the browser.
The DataShare REST API page starts with a link to our plain-English explanation of how the API can be used:
Edinburgh DataShare DSpace REST API
We would like to hear from anyone who wants to use the API. Please try it out and let us know what you find useful! Email us at data-support@ed.ac.uk .
Examples using the graphical query builder
I wanted to find datasets where I could add a link to the associated publication. This is a bit of a challenge for us, since users typically deposit their data with us under embargo before the associated paper has been published, and we do not have an automatic way to detect when or whether an associated publication has appeared. I used the query builder to find the IsReferencedBy value for deposits accessioned in 2017. The plain-English guide on the wiki provides the steps I went through to do so:
How to use the DataShare REST API
This feature may be of use to colleagues who support organisational units at University of Edinburgh which don’t align precisely with the Collections structure of DataShare – the API lets you query on multiple collections through the reporting tool. We’d love for colleagues to contact us if their teams have published a new paper containing a data citation of their DataShare deposit, so we can add the details of the publication to the DataShare Item’s metadata, resulting in a hyperlink appearing on the dataset landing page.
I wanted to find datasets with an embargo date in December. This is a challenge for us because users often set their embargo expiry date to Hogmanay, which means their one-week reminder would arrive on Christmas Day right in the middle of the university’s winter break. But many other fields contain dates with December in them, so it has not been practical for me to search for this using the graphical interface. So I used the API to search specifically in the dc.date.embargo field. See the screenshot below. The API helped me find the datasets whose embargo date we needed to extend, or else lift the embargo outright, allowing us to contact the depositors in good time to ask them whether a paper had been published or more time was needed.
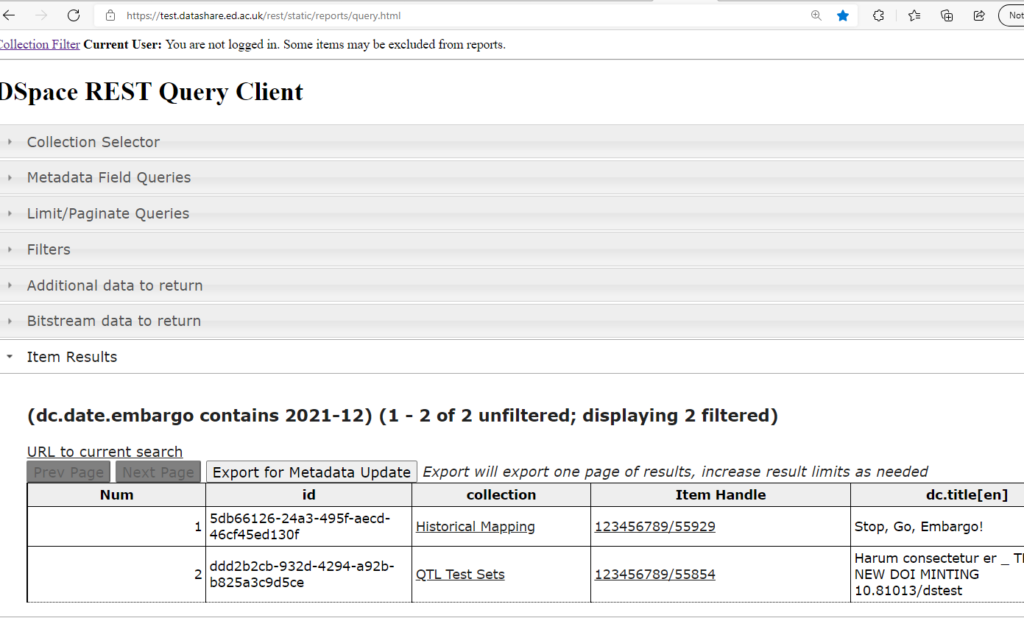
Results showing datasets with an embargo date in December 2021
Thirdly, to demonstrate the power of this tool relative to the non-specific Search I chose a topic with very common words to show how to use the query builder to focus in on results avoiding spurious matches.
Using the existing ‘Search’ function on the homepage I searched for ‘history Scotland’. This produced 39 matches, some of which have nothing to do with historical research or Scotland, but merely mention a funder “NHS Research Scotland”, and mention the history of the research field in passing to provide a little context. Most of the matches are interesting, but some are not relevant.
Whereas when I set the API query builder to search for ‘history’ in the research area (subject classification), and ‘Scotland’ in the field for geographical metadata ie dc.coverage.spatial. This provided me with a short list of high quality matches, three datasets of historical research to do with Scotland – see the screenshot. This is a useful tool for narrowing a search.
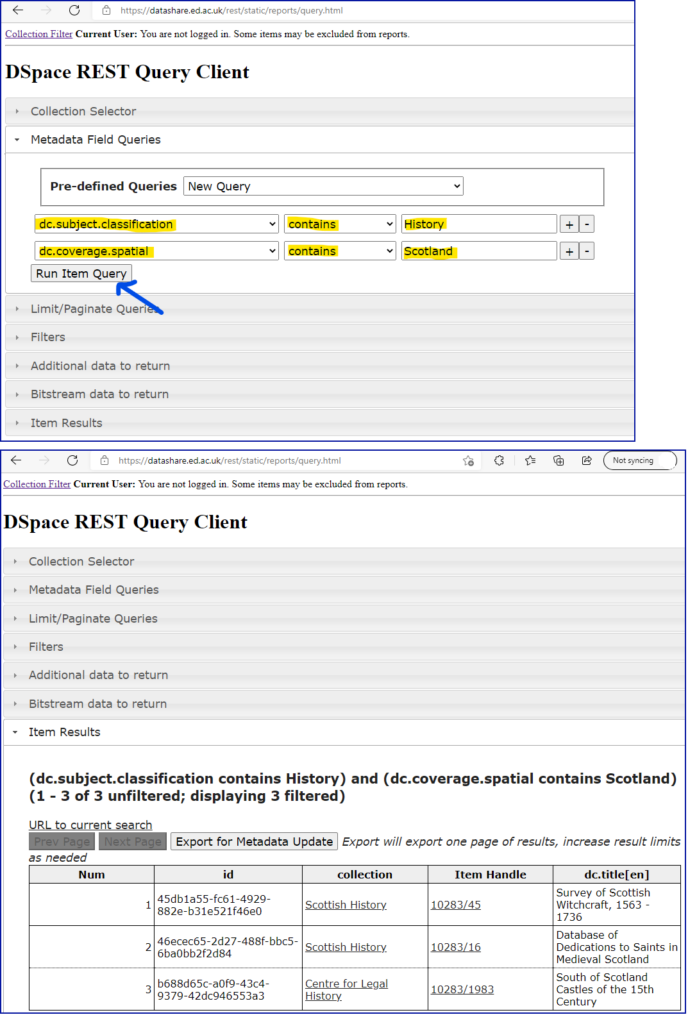
A search for two very common words in specific fields produces high quality results
Enabling the API
The REST API is a feature of the underlying DSpace repository software. Our sysadmins configured the API with great care to block certain commands and enable only the ‘GET’ commands that are needed for appropriate queries using DSpace config settings (further info DSpace 6 Documentation on the Lyrasis wiki ).
The Future
In the international DSpace repository community, we’re aware the API is used for integration with at least one CRIS (Current Research Information System) and quality tool applications (Andrea Bollini, 4Science, private communication). We understand the API of the newer DSpace 7 contains significant changes compared to that of DSpace 6, which we’re using for Edinburgh DataShare.
We’re aware of only a few examples of the API being used by individuals for occasional metadata queries. But we will watch with interest to see how the DSpace 7 API will be used.
Pauline Ward
Research Data Support Assistant
Library and University Collections
University of Edinburgh