
Warning: Undefined array key "file" in /apps/www/wordpress/blogs/wp-includes/media.php on line 1686
[Reposted from https://libraryblogs.is.ed.ac.uk/blog/2013/12/12/thinking-about-research-data-asset-registers/]
In my last blog post, I looked at the four quadrants of research data curation systems. This categorised systems that manage or describe research data assets by whether their primary role is to store metadata or data, and whether the information is for private or public use. Four systems were then put into these quadrants.
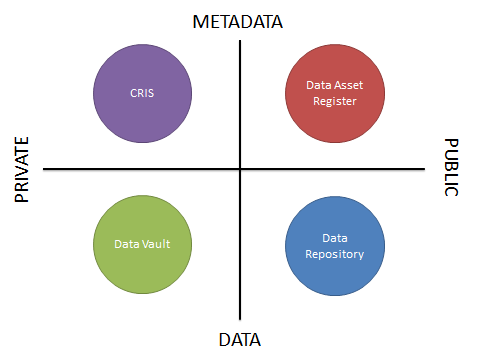
The University of Edinburgh already has two active services from this diagram: PURE, our Current Research Information System and DataShare, our open data repository.
This blog post will start to unpack some of the requirements for a Data Asset Register.
The first aspect to cover is its name. What should it be called? Traditionally systems like this, which only hold metadata records that either just describe, or describe and point to other resources, are known as registers, catalogues, directories, indexes, or inventories.
The University already has a ‘Data Catalogue’, maintained by the Data Library. However this list has a different purpose, to hold details of external data. Oxford University, instead of opting for a name such as this, have instead opted to call their service by the verb ‘find’ – DataFinder. Whilst there may be some brand or service name applied to the system we create at the University of Edinburgh, for now its working title is ‘Data Asset Register’ as one of its main functions will be to allow data creators to ‘register’ their data assets by describing them, and if the data is published online to link to the data.
But what should the Data Asset Register provide? The following diagram shows some early thoughts:
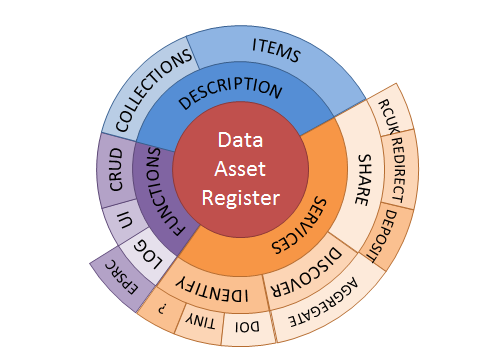
The diagram splits this up into three broad areas:
- Description – what the asset register should describe
- Functions – the functions needed to allow data asset description
- Services – the value-added services that will add benefit to people who register their data
Description
The core purpose of the system is to describe data. This is split into two categories: being able to describe single items or data assets, and describing collections of data assets. Many data assets are created on their own, for example a population health longitudinal study. As such, this should be described on its own. In contrast, some data are created in large sets, where it isn’t necessarily useful to describe every part of that set on its own. In this case, the collection as a whole can be described. A good example of this is the Research Data Australia service from the Australian National Data Service.
We’ll need to decide how to describe the data. A likely initial candidate will be the DataCite Metadata Schema, but we may find this needs to be extended to cover extra elements relevant to the University or the discipline of the data asset being described. There will also be requirements coming from a possible UK research data registry, development of which is being led by the Digital Curation Centre.
Functions
In order to enable data asset description, a register will need certain functions. So far three have been identified:
- CRUD: Create / Read / Update / Delete are the basic functions required when manipulating data. The system should allow records of research data to be created, read later, updated, and if needed, deleted.
- User Interface (UI): In order to enable CRUD functionality, a user interface will be required. To be useful, this will need to provide search and display functionality, for example using faceted search and browse.
- Log: Some funders have requirements to keep data for certain lengths of time, or for periods of time that must be reset each time a data set is accessed. For this reason each access of a data asset must be logged by the system. An example is from the EPSRC:
“Research organisations will ensure that EPSRC-funded research data is securely preserved for a minimum of 10-years from the date that any researcher ‘privileged access’ period expires or, if others have accessed the data, from last date on which access to the data was requested by a third party;”
It may also be that the Data Asset Register can be a front-end for our Data Vault too – more about that in another blog post!
Services
Extra value-added services are required in order to make the Data Asset Register useful to people. Our initial thoughts about these services include the following:
- Identify: The ability to assign identifiers to data assets. Some of these identifiers will need to be persistent.
- DOI: DataCite DOIs allow DOIs to be assigned to data assets, in the same way that DOIs are assigned to journal articles. This allows them to be persistently identified over time even if they move between systems, but also allow them to be cited using a well-known identifier.
- TinyURL: A short URL such as those provided by TinyURL or bitly are useful to give easy web identifiers to objects. For example it might be nice to be able to issue URLs such as http://data.ed.ac.uk/abcd.
- Other: Are there any other identifier systems that we should consider using?
- Discover: It is important that the data records held in the Data Asset Register are searchable and can be indexed by external services. This may be by national, international, or discipline-based data aggregators, or by normal web search engines.
- Share: Whilst often the data assets will be described online but kept offline by the researcher, they may wish to share the data. The Data Asset Register may need to facilitate this in a number of ways:
- Deposit: If the data is held in the Data Vault, along with a description in the Data Asset Register, then using a deposit protocol such as SWORD it would be possible to deposit the data into the institutional data repository, or into an external repository. The Data Asset Register can then record the identifier for the hosted data set.
- Redirect: Where the data is hosted online elsewhere, the Data Asset Register could automatically redirect users. For example visiting http://data.ed.ac.uk/abcd could redirect a visitor directly to the repository, rather than showing them just the data asset record description. If the data is not shared openly, then contact details can be provided of the data owner.
- RCUK: Some funders, such as the RCUK members (Research Councils UK) require funded journal papers to include “a statement on how the underlying research materials – such as data, samples or models – can be accessed”. The data asset register could facilitate this by automatically writing statements such as “Details about accessing the data referenced in this paper may be found at http://data.ed.ac.uk/abcd”
It is very early days in our thinking about what features a Data Asset Register should offer, and like many components of a modern research data management infrastructure, there are very few existing examples to look at. Our thoughts will be refined over the coming months so that we can start looking at implementation options. Is there an existing system that can do all of this for us, or is it better to build something new, either alone or with collaborators?
Images available from http://dx.doi.org/10.6084/m9.figshare.873617
Stuart Lewis, Head of Research and Learning Services, Library & University Collections.