
For 2023/2024, Digital Research Services have organised a new iteration of the Lunchtime Seminar Series. These one-hour hybrid seminars will examine different slices of the research lifecycle and introduce you to the data and computing expertise at the University of Edinburgh.
The seminars have been designed to answer the most common questions we get asked, offering valuable bite-sized learning opportunities for research staff, postgraduate research students, and professional staff alike. You will gain an understanding of how digital research fits in with wider research support teams and good research practices. Your sessions will cover research funding, research planning, tailored skill development, data management and advancements in AI.
Oh, and did we mention there is free lunch for in-person attendees? That is truly the cherry on top.

DRS Lunchtime Seminars – 2024 Calendar
Have a look at the upcoming seminars:
Seminar 1: How to plan and design your research project better. 22nd January 12:00 – 13:00
This session is all about making sure researchers head off with a strong start. Did you know that the University has tools that help you optimise your data management plan, with funder specific templates and in-house feedback? We will make sure you get the best use out of DMPOnline and the Resource Finder Tool. We will also introduce you to some key concepts in data management planning, research funding and digital skill development.
Seminar 2: How to store and organise your data properly. 27th February 12:30-13:30.
Discover how to best store and organise your data using University of Edinburgh’s tools: DataStore, DataSync and GitLab. If you work in a wet lab, you might be particularly interested in electronic lab notebooks. We will introduce you to the functionalities of RSpace and protocols.io. Finally, the University has just launched an institutional subscription to the Open Science Framework (OSF). You will discover that it is much more than a tool for data storage, as it can help manage complex workflows and projects as well.
Seminar 3: How to interpret and analyse your data efficiently. 13th March 12:00-13:00
This seminar is mainly about big computers, such as UoE’s Eddie and Eleanor. Through EPCC, researchers can get also access to large scale national supercomputers, such as Archer and Cirrus. At the same time, we will show a glimpse on some developments on the AI front.
Seminar 4: How to manage, publish, share and preserve your work effectively. 2nd April 12:00-13:00
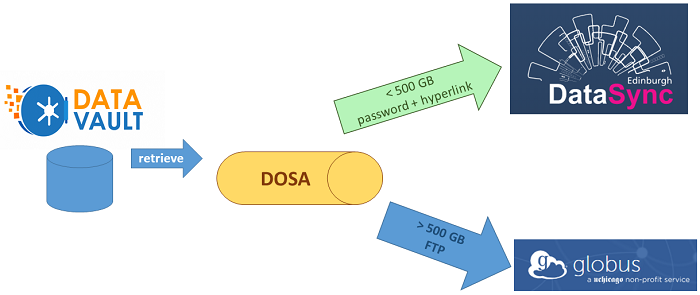
The final seminar is all about making sure your work is published and preserved in the best way. We will talk you through different (open access) publishing pathways such as Journal Checker, Edinburgh Research Archive, Read & Publish journal list, Edinburgh Diamond. We will also be talking about data repositories (e.g. DataVault, DataShare) and our research output portal, Pure.
For info and booking:
https://digitalresearchservices.ed.ac.uk/training/drs-seminars
Blog post by Dr Sarah Janac
Research Facilitator – The University of Edinburgh


 Thirdly,what services are provided to researchers to make their work public? Most universities provide support like a data repository (except for LSE), Research Data Management support, Open Access to publications and thesis and guidance on sharing research software. A few provide support on protocols sharing. Some universities have started hosting an open research conference. For example, UCL Open Science Conference 2021, 2022,
Thirdly,what services are provided to researchers to make their work public? Most universities provide support like a data repository (except for LSE), Research Data Management support, Open Access to publications and thesis and guidance on sharing research software. A few provide support on protocols sharing. Some universities have started hosting an open research conference. For example, UCL Open Science Conference 2021, 2022,