The Research Data Service team applauds those researchers at the University of Edinburgh who share their data. We therefore decided to show our appreciation by presenting awards to our most successful depositors, as part of the Dealing With Data conference. The prizes themselves do not come with a cash research grant attached unfortunately. However, the winners did receive a certificate bearing an image of our mascot for the day, Databot. We think you’ll agree the winning depositors and their data demonstrate the diversity of our collections, in terms of subject matter, formats and sheer size. We were particularly pleased with the reactions from both the recipients and the attendees, both in person, by email and on twitter (#UoEData was the Dealing with Data hashtag). Who doesn’t love the drama of an awards ceremony! A video is available.

Photo: CC-BY Lorna M. Campbell
The winners in full…
MOST DATASHARING SCHOOL: Edinburgh Medical School
– the School which boasts the greatest number of Edinburgh DataShare Collections currently. Thirty-three eligible Collections (already containing at least one dataset) such as “Connectomic analysis of motor units in the mouse fourth deep lumbrical muscle”, the Edinburgh Imaging “Image Library” and “Generation Scotland”.
MOST PROLIFIC DATASHARER: Professor Richard Baldock
– the most prolific depositor into Edinburgh DataShare for the academic year 2016-17, and over the lifetime of the repository, having shared a grand total of 1,105 data items with full metadata. These are grouped together into numerous Collections under the heading of “e-Mouse Atlas”. The majority of these detailed images show microscope slides of stained tissue, others are 3D models. They accompany a book and website published by Professor Baldock, building on the seminal work of Professor Matt Kaufman in developmental biology. The metadata for each of the slides links to a lower definition version within the e-Mouse Atlas website, where the data may be viewed and navigated in context. The original slides themselves are held by the University’s Centre for Research Collections.
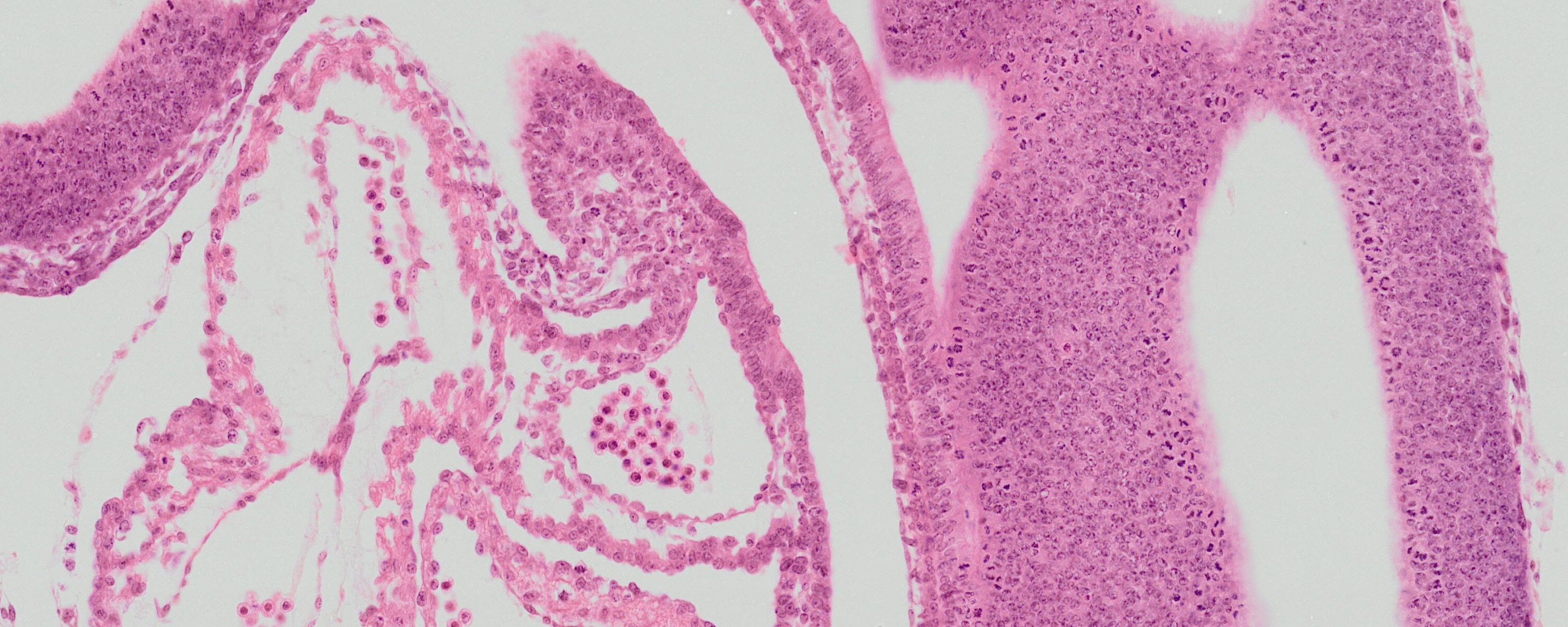
Detail from Elizabeth Graham; Julie Moss; Nick Burton; Yogmatee Roochun; Chris Armit; Lorna Richardson; Richard Baldock. (2015). eHistology Kaufman Atlas Plate 21a image d, [image]. University of Edinburgh. College of Medicine and Veterinary Medicine. http://dx.doi.org/10.7488/ds/735.
– the depositor of the greatest number of Edinburgh DataShare items from the College of Science and Engineering in academic year 2016-2017. Euan deposits his coordination chemistry research data so frequently that we set up a Collection template on the Brechin Research Group, which automatically pre-populates some of the metadata fields for him, saving Euan time. If only we could find a way to mention metallosupramolecular cubes here.

The certificate awarded to Professor Euan Brechin
MOST PROLIFIC DATASHARER (CAHSS): Dr Andrea Martin
– the depositor of the greatest number of Edinburgh DataShare items from the College of Arts, Humanities and Social Sciences in academic year 2016-2017. Some of these “Language Cognition and Communication” data items are still under temporary embargo. Users may nonetheless see all the metadata.
MOST POPULAR SHARED DATA: Professor Peter Sandercock
– the depositor of the Edinburgh DataShare item which has attracted the greatest number of page views over the lifetime of the repository: “International Stroke Trial database (version 2)” (aka IST-1). These data from the International Stroke Trial provide a great example of how clinical trial data may be anonymised to allow them to be shared. For more information, you may want to watch Prof Sandercock’s very accessible and detailed public lecture. Admittedly, one other item is higher up DataShare’s table of page views than IST. However we believe the traffic drawn by “RCrO3-xNx ChemComm 2016” to be artifactual, arising from the appearance of the word ‘doping’ in its abstract, and the fact the deposit was made at a time when doping in sport was very prominent in the news media. Additionally, the earlier, superseded, version of the IST-1 dataset also appears in the all-time top ten, and if we combine the number of views, it is in the No.1 spot outright 🙂
MOST POPULAR DATA 2016-17: Dr. Junichi Yamagishi
– the depositor of the Edinburgh DataShare item which has attracted the greatest number of page views (1,720 to be precise, as counted by Google Analytics) over the academic year 2016-17: “Automatic Speaker Verification Spoofing and Countermeasures Challenge (ASVspoof 2015) Database”. Here’s the suggested citation, which DataShare compiles automatically, and displays prominently, to encourage users to cite the data:
Wu, Zhizheng; Kinnunen, Tomi; Evans, Nicholas; Yamagishi, Junichi. (2015). Automatic Speaker Verification Spoofing and Countermeasures Challenge (ASVspoof 2015) Database, [dataset]. University of Edinburgh. The Centre for Speech Technology Research (CSTR). http://dx.doi.org/10.7488/ds/298.
MOST POPULAR DATA 2016-17 (CAHSS): Professor Miles Glendinning
– the depositor of the Edinburgh DataShare item from the College of Arts, Humanities and Social Sciences which has attracted the greatest number of page views (1,374 to be precise, as counted by Google Analytics), over the academic year 2016-17: “Hong Kong Public Housing Archive”. The Research Data Service is working closely with Miles, Personal Chair of Architectural Conservation, on a series of batch imports to put his fabulous array of photographs of public housing tower blocks from all around the world on DataShare over the coming months – keep an eye on DOCOMOMO International Mass Housing Archive.

Image cropped from “HKI_H_Yue_Fai_Ct.jpg” from Glendinning, Miles; Forsyth, Louise; Maxwell, Gavin; Wood, Michael. (2015). Hong Kong Public Housing Database, 2006-2015 [image]. University of Edinburgh. Edinburgh College of Art. http://dx.doi.org/10.7488/ds/322.
– the depositor of the Edinburgh DataShare Collection page from the College of Medicine and Veterinary Medicine which has attracted the greatest number of page views over the academic year 2016-17: “Diseases of Wild Birds”. Hundreds of grotesquely beautiful photographs of dead wild birds, bodies ravaged with viruses, bacteria and protists, found at locations all around the United Kingdom; these images support the PhD thesis of Dr Tom Pennycott from our Veterinary School.
You can see usage statistics for any DataShare Item or Collection simply by clicking on the “View usage statistics” button on the right-hand-side of the page.
Pauline Ward, Research Data Service Assistant
EDINA and Data Library