Over the spring of 2019 the Research Data Service (RDS) is holding a series of workshops with the aim of gathering feedback and requirements from our researchers on a number of important Research Data topics.
Each workshop will consist of a small number of short presentations from researchers and research support staff who have experience of the topic. These will then be followed by guided discussions so that the RDS can gather your input on the tools we currently provide, the gaps in our services, and how you go about addressing the challenges and issues raised in the talks.
The workshops for 2019 are:
Electronic Notebooks 1
14th March at King’s Buildings (Fully Booked)
DataVault
1200-1400, 10th April at 6301 JCMB, King’s Buildings, Map
Booking Link – https://www.events.ed.ac.uk/index.cfm?event=book&scheduleID=34308
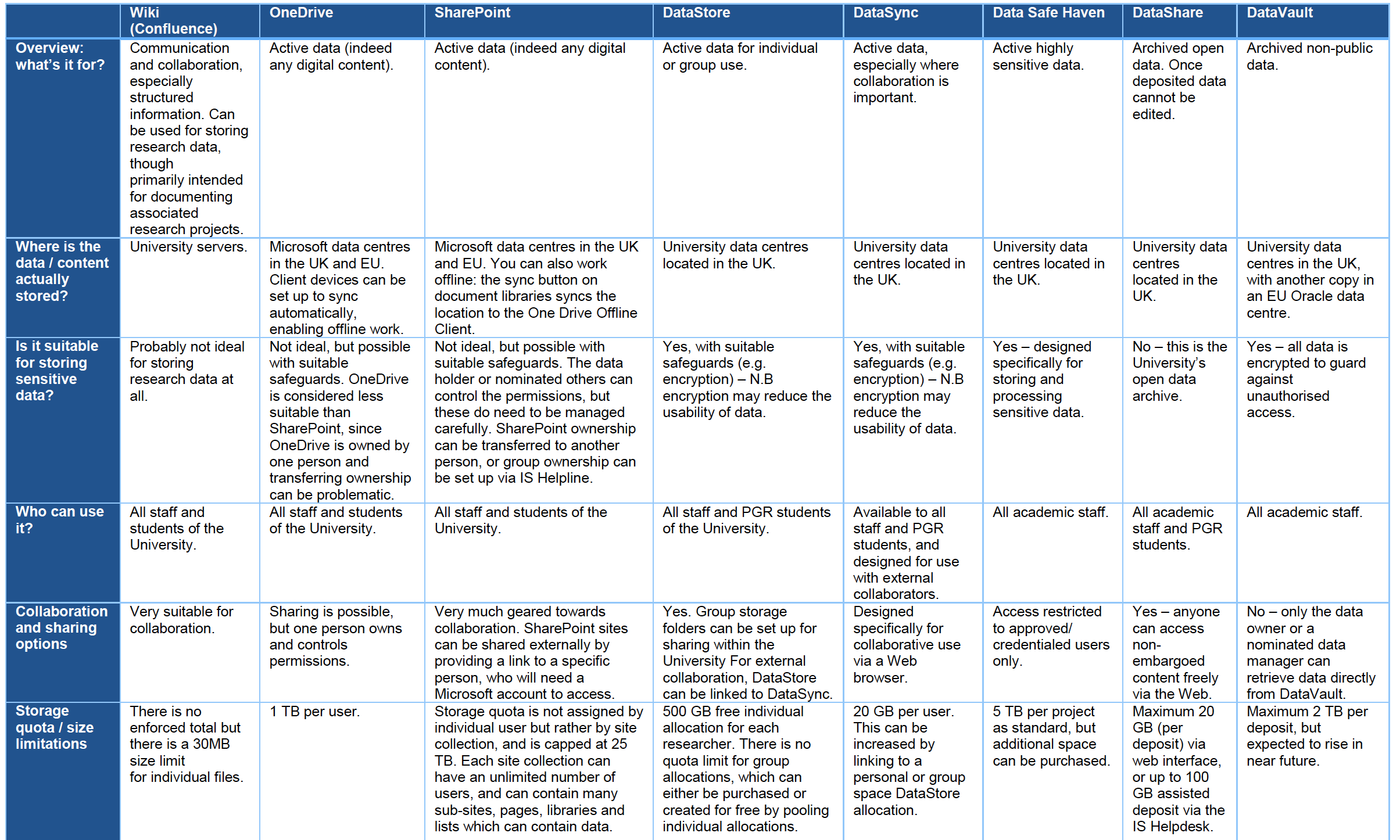
The DataVault was developed to offer UoE staff a long-term retention solution for research data collected by research projects that are at the completion stage. Each ‘Vault’ can contain multiple files associated with a research project that will be securely stored for an identified period, such as ten years. It is designed to fill in gaps left by existing research data services such as DataStore (active data storage platform) and DataShare (open access online data repository). The service enables you to comply with funder and University requirements to preserve research data for the long-term, and to confidently store your data for retrieval at a future date. This workshop is intended to gather the views of researchers and support staff in schools to explore the utility of the new service and discuss potential practicalities around its roll-out and long-term sustainability.
Sensitive Data Challenges and Solutions
1200-1430, 16th April in Seminar Room 2, Chancellors Building, Bioquarter, Map
Booking Link – https://www.events.ed.ac.uk/index.cfm?event=book&scheduleID=34321
Researchers face a number of technical, ethical and legal challenges in creating, analysing and managing research data, including pressure to increase transparency and conduct research openly. But for those who have collected or are re-using sensitive or confidential data, these challenges can be particularly taxing. Tools and services can help to alleviate some of the problems of using sensitive data in research. But cloud-based tools are not necessarily trustworthy, and services are not necessarily geared for highly sensitive data. Those that are may not be very user-friendly or efficient for researchers, and often restrict the types of analysis that can be done. Researchers attending this workshop will have the opportunity to hear from experienced researchers on related topics.
Electronic Notebooks 2
1200-1430, 9th May at Training & Skills Room, ECCI, Central Area, Map
Booking Link – https://www.events.ed.ac.uk/index.cfm?event=book&scheduleID=34287
Electronic Notebooks, both computational and lab-based, are gaining ground as productivity tools for researchers and their collaborators. Electronic notebooks can help facilitate reproducibility, longevity and controlled sharing of information. There are many different notebook options available, either commercially or free. Each application has different features and will have different advantages depending on researchers or lab’s requirements. Jupyter Notebook, RSpace, and Benchling are some of the platforms that are used at the University and all will be represented by researchers who use them on a daily basis.
Data, Software, Reproducibility and Open Research
Due to unforeseen circumstances this event has been postponed. We will update with the new event details as soon as they are confirmed.
In this workshop we will examine real-life use cases wherein datasets combine with software and/or notebooks to provide a richer, more reusable and long-lived record of Edinburgh’s research. We will also discuss user needs and wants, capturing requirements for future development of the University’s central research support infrastructure in line with (e.g.) the LERU Roadmap for Open Science, which the Library Research Support team has sought to map its existing and planned provision against, and domain-oriented Open Research strategies within the Colleges.
Kerry Miller
Research Data Support Officer
Library & University Collections