
‘Code red for humanity’ was the galvanising message of the sixth report of the Intergovernmental Panel on Climate Change published on 9 August. The report draws on thousands of academic research projects. Research data is vital to understanding the nature and scale of the challenge of climate change, and the necessary deployment and application of solutions.
We decided to draw together the datasets relating to climate change to showcase them on a single Collection page on Edinburgh DataShare, our research data repository. In part this was prompted by a new deposit from Oliver Escobar in the School of Social and Political Science – data from citizens’ assemblies debating wind farms. Our DSpace repository allows us to ‘map’ an Item to Collections other than the one to which it belongs, resulting in the dataset being listed in more than one Collection. Edinburgh DataShare contains a wealth of research datasets from an extremely diverse array of academic disciplines, reflecting the strengths of the University of Edinburgh, and so it is with our climate change research:
We added many datasets from our School of Geosciences: one dataset from Ian Goddard and Professor Simon Tett demonstrated how urbanisation has affected temperatures in the UK, and includes a map showing heat islands around our major cities. Professor Tett said:
“To truly understand how climate change might impact society we need to bring together many datasets developed by many researchers so that other researchers can use them for their own studies. DataShare enables this.”
Goddard, Ian; Tett, Simon. (2018). “Software and data used in the study ‘How much has urbanisation affected temperatures in the United Kingdom'”, 1990-2017 [software]. University of Edinburgh. https://doi.org/10.7488/ds/2370.
Climatological data and toolkits for public engagement around climate and natural resources came from Professor Marc Metzger – including various kinds of maps, a board game and posters showing natural resources.
One dataset was a description of an artwork, a quilt representing global temperature measurements. Posters on the wall show the years, so as to provide a time axis for the temperature data represented in the colours of the patches in the quilt:

World temperature quilt on display at the Data-X exhibition
Zaenker, Julia; Vladis, Nathalie. (2017). Feel The Heat – A World Temperature Data Quilt, [image]. University of Edinburgh. EDINA. https://doi.org/10.7488/ds/1998.
Another theme was renewable energy – we included data from our School of Engineering on tidal turbines, and recent wave buoy experimental data:
The big 3-0-0-0: DataShare reaches three thousand datasets
All this raises the question – why bring these data together, what for? Do the datasets measuring and defining the problem really belong with the research working on technology to reduce greenhouse gas emissions? To answer this, I think the analogy of our other thematic collection on Covid-19 is apt. To develop and implement effective treatments and public health responses to Covid-19, we do need to understand a great deal about the cause, the pathogen and the pathology it creates. We should strive to break down barriers between domains of knowledge. So yes, to tackle climate change more effectively, we should all seek to better understand the underlying processes and the behavioural and technological solutions we must employ.
By bringing together research data from diverse teams in a single DataShare Collection, we empower the user to browse those datasets using the ‘facets’ feature in DataShare, or indeed a text search within the Collection. The user can filter by geography, by data creator’s name, by keyword, funder (see the screenshot below) or they can choose their own search term. When they reach an individual dataset, the breadcrumb trail at the top of the page can lead them into the original Collection where the dataset was first deposited, leading them to other work from the same research group, centre or School. This is one small way for the curation team to enhance the findability of the data. Scientists tell us there are challenges posed by the plethora of formats and programming languages used, even within disciplines. We hope that by making the connections and common themes between these different strands of research from different disciplines more visible, we make the data more findable, and perhaps hope to inspire new research questions or approaches.
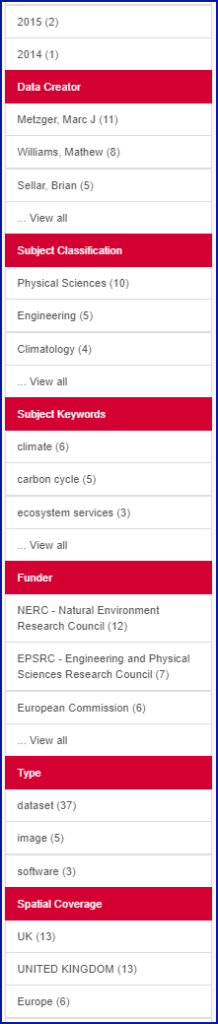
DataShare’s facets
A word about DataShare’s structure: we find our depositors prefer to place their data in a Collection that reflects the organisational placement of their research group – typically the Collection represents the research group, and sits within a Community representing a research centre, sitting within a Community representing a School, sitting within a top-level Community representing a College:
DataShare structure
If you would like to suggest a theme for a new thematic Collection on DataShare, please contact the Research Data Support team:
Research Data Service | Contact
The RDS team, like all the University of Edinburgh’s teams, has a remit to address climate change as the university is committed to contributing to the UN’s Sustainable Development Goals, including no. 13 “Take urgent action to combat climate change and its impacts”:
Social Responsibility and Sustainability | The University of Edinburgh
We can all learn more about how we can take that urgent action effectively on the university’s amazing and inspiring “Climate Solutions” MOOC, available on edX:
Climate Solutions | edX
I recommend anyone to take this course – it is free of charge, it’s fun, it is easy to fit around other commitments. I’ve nearly completed the coursework and already passed thanks to my quiz scores, got my nice PDF certificate signed by Professor Dave Reay. The Climate Solutions MOOC inspired me to create the Climate Change thematic Collection and it has really opened my eyes to the scale and nature of the challenge, and many actions we all need to take to contribute to halting the rise in global temperatures. Everyone has their part to play.
Pauline Ward
Research Data Support Assistant
Library & University Collections
University of Edinburgh

