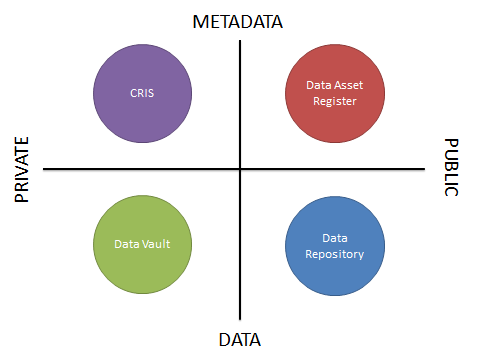
Data Seal of Approval have awarded DataShare Trusted Repository status; their assessment of our service can be read at https://assessment.datasealofapproval.org/assessment_175/seal/html/. In addition a major new release of DataShare was completed in November, this makes the code open in Github as well as making general improvements to the look and feel of the website.
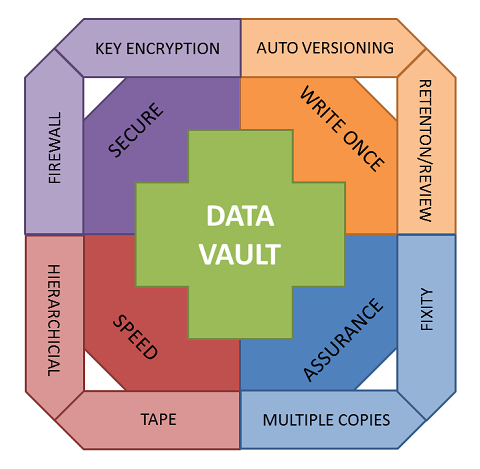
The ‘interim’ DataVault is now in final testing and will be rolled out on a request basis to those researchers who can demonstrate an urgent need to use the service now rather than waiting until the final version is ready later this year. The phase three funding for development of the DataVault has been received from Jisc, this runs from March to August, so the final version should be ready for launch sometime after this. The project was presented at the International Digital Curation Conference in February 2016.
Over the three month period a total of 328 staff and postgraduate researchers have attended a Research Data Management (RDM) course or workshop.
Work on the MANTRA MOOC (Massive Open Online Course) was expected to be finalised in February and launched on 1st March, at the following URL: https://www.coursera.org/learn/data-management.
University of Edinburgh wrote the Working with Data section (one out of 5 weeks of the course) and with the help of the Learning, Teaching and Web division of Information Services completed two video interviews with researchers and a ‘vox pop’ video clip of clinical researchers at the EQUATOR conference in Edinburgh in autumn, 2015. The content is open source and videos can be added to our YouTube channel to help with promotion. There will be some income from this, but a smaller portion than our partner, the University of North Carolina, based on certificates of completion priced at $49 or £33.
The need to create a dataset record in PURE for each dataset published, or referenced in a publication, is now being emphasised in all Research Data Service communications, formal and informal, and to staff at all levels. Uptake is understandably low at this point but we hope to see a steady increase as researchers and support staff begin to see the benefits of adding datasets to their research profile. In the case of DataShare records, a draft mapping of fields between DataShare and PURE has been produced as a start of a plan for migrating records from DataShare to PURE.
By the end of January 2016, 69 records had been created and published on Edinburgh Research Explorer.
Four interns have been employed using funding from Jisc as part of the UK Research Data Discovery Service (UKRDDS) project which aims to create a national aggregate register of data sets. A trial site is available at: http://ckan.data.alpha.jisc.ac.uk/. The UKRDDS interns will help to create PURE records and upload open data into DataShare, and raise awareness of RDM generally within their schools. There are currently three PhD interns in place in LLC, SOS, and Roslin, two more in LLC, & DIPM will start in February. The approach each intern takes will depend on the nature and structure of their school and will, in some cases, be mediated by research administrators.
An innovation fund grant has been received to fund the delivery of an exhibition “Pioneering Research Data”. Each college will be represented by a PhD intern, the recruitment of these has already begun and they should be in post by the end of March. The Exhibition is due to be delivered in November of this year.
National and International Engagement Activities
Robin Rice led a panel at the IPRES conference, Chapel Hill, North Carolina, on 3rd November called ‘Good, better, best’? Examining the range and rationales of institutional data curation practices’.
Robin Rice had a proposal accepted for the forthcoming Force11 (2016) conference, on Overcoming Obstacles to Sharing Data about Human Subjects, building on the training course we are delivering, Working with Personal and Sensitive Data.
Kerry Miller
RDM Service Coordinator