
On the 30 October 2013 the University of Edinburgh (UoE) organised what I believe to be the first University wide meeting on Electronic Lab Notebooks (ELN), and allowed a number of Principal Investigators (PIs) and others the opportunity to provide useful feedback on their user experiences. This provided an excellent opportunity to help discuss and inform what the UoE can do to help its researchers, and whether there is likely to be one ‘solution’ which could be implemented across the UoE or if a more bespoke and individual/discipline specific approach would be required.

Lab Notes by S.S.K. – Flickr
Good research and good research data management (RDM) stem from the ability of researchers to accurately record, find, retrieve and store the information from their research endeavours. For many, but by no means all, this will initially be done by recording their outputs on the humble piece of paper. Albeit one contained within a hardbound notebook (to ensure an accurate chronological record of the work) and supplemented liberally with printouts, photographs, x-rays, etc. and reminders of where to look for the electronic data relevant to the day’s work (ideally at least).
Presentations from University researchers
Slides from these presentations are available to UoE members via the wiki.
The event kicked off with a live demonstration from the member of the School of Physics & Astronomy, and his positive experiences with the Livescribe system. This demonstration impressively articulated the functions of the electronic pen, which allows its user to record, stroke by stroke, their writings, and pass on this information either as a movie or document to others, and store the output electronically. Although there were some disadvantages noted, such as the physical size of the pen and the reliance on WiFi for certain features, and that to date, only certain iOS 7 devices are supported (although this list will grow in 2014). Clearly, this device has had a positive effect on both the presenter’s research and teaching duties. However the livescribe pen does not in itself help address how to store these digital files.
The remainder of the presentations from the academic researchers were from the fields of life science, although their experiences were quite diverse. This helpfully provided a good set-up for a healthy discussion, on both ELNs and indeed the wider aspects of RDM at the UoE.
Of the active researchers who presented, two were PIs from the School of Molecular, Genetic and Population Health Sciences and one was a postdoctoral researcher from the School of Biological Sciences. All three had prior experience in using previous versions of ELNs, and had sought an ELN to address a range of similar issues with paper laboratory notebooks.
Merits and pitfalls of electronic notebooks
I have chosen not to provide feedback on the specific ELNs trialled here, but the software discussed was Evernote, eCAT, and Accelyrs, and as the UoE does not recommend or discourage the use of any particular ELN to-date, I won’t either.
In all cases these electronic systems were purchased for help with key areas:
Motivation/Benefits
- Searchable data resource
- Safe archive
- Sharing data
- Copy and paste functions
- Functionality for reviewing lab member’s progress
- Ability to organise by experiments (not just chronologically)
- One system to store reagents/freezer contents with experimental data
And in general, key problematic issues raised with these systems were:
Barriers/Problems
- Need for reliable internet access
- Hardware integration into lab environment
- Required more time to document and import data
- Poor user interface/experience
- Copy and paste functions (although time-saving, may increase errors as data are not reviewed)
- Administration time by PI is required
- PhD students and postdocs (when given the choice*) preferred to use paper notebooks
*it was mooted that no choice should be given.
Infrastructure
A common theme with the use of ELNs was that of the hardware, and the reliance on WiFi. Clearly when working at the bench with reagents that are potentially hazardous (chemicals, radiation, etc) or with biologicals that you don’t wish to contaminate (primary cell cultures for instance) the hardware used is not supposed to be moved between such locations and ‘dry areas’ such as your office. A number of groups have attempted to solve this problem by utilising tablets, and sync to both the “cloud” and their office computers, and this is of course dependent on WiFi. Without WiFi, you might unexpectedly find yourself with no access to any of your data/protocols, which leads to real problems if you are in the middle of an experiment. Additionally this requires the outlay of monies for the purchase of the tablets, and provides a tempting means of distraction to group members (both of which may be frowned upon by many PIs). This monetary concern was identified as a potential problem for the larger groups, where multiple tablets would be required.
Research Data Management & Electronic Laboratory Notebooks
From an RDM perspective the subsequent discussions raised a number of interesting issues. Firstly, as a number of these ELN services utilise the “cloud” for storage, it was clear that many researchers, PIs included, were unaware of what was expected from them by both their funding councils and the UoE.

Secure Cloud Computing by FutUndBeidl – Flickr
The Data Protection Act 1998 sets out how organisations may use personal data, and the Records Management Section’s guidance on ‘Taking sensitive information and personal data outside the University’s secure computing environment’ details the UoE position on this matter, but essentially all sensitive or personal information leaving the UoE should be encrypted. This guidance would seem not to have reached a significant proportion of the researchers yet.
ELN? – not for academic research!
Whilst the first two presentations were broadly supportive of ELNs, the third researcher’s presentation was distinctly negative, and he provided his interpretation on the use of an ELN in an academic setting. Although broadly speaking this presentation was on one product, it was made clear that his opinions were not based on one ‘software product’ alone. In this case the PI has since abandoned the ELN (after four years of use and requiring his lab members to use it), citing reasons of practicality; it took too long to document the results (paper is always quicker), there is no standard for writing up documentation online**, and the data have effectively been stored twice.
He was also of the strong opinion that the use of ELNs:
“were not going to improve your research quality – it’s for those who want to spend time making their data look pretty.”
And –
“it is not for academic research, but more suited for service labs and industry.”
These would seem to be viewpoints that cannot easily be addressed.
The role of the PI
**Of course this is also true for paper versions, with the National Postdoctoral Association (USA) noting in their toolkit section on ‘Data Acquisition, Management, Sharing and Ownership’ that with the multinational approach to research that:
“many [postdocs] may prefer to keep their notes in their native language instead of English. Postdoc supervisors need to take this into consideration and establish guidelines for the extent to which record keeping must be generally accessible.”
The role of the PI cannot be overlooked in this process and to-date, even if a paper notebook is utilised, there is often no standard to observe.
The next generation of ELNs
Despite these concerns ResearchSpace Ltd are poised to release the next generation of an ELN, with an enterprise release of their popular eCAT ELN, to be called RSpace. The RSpace team seem confident that they are both aware and capable of addressing these various user requirements and it will certainly be interesting to see how they get on. Certainly they provided clear evidence of improved user interfaces, enhanced tools, knowledge of University policy, with the prospect of integration into the existing UoE digital infrastructure, such as the data repository, Edinburgh DataShare.
Researcher engagement
Importantly whilst this programme identified concerns and benefits with the various software systems available, it also highlighted issues with the UoE dissemination of RDM knowledge to the research community, and so perhaps fittingly the last word will be from the chair:
“The University has a lot of useful information on this area of data management; please look at the research support pages!”
So the fundamental question remains, what is the best way to engage researchers in RDM and how can we best address this need at all levels?
Links
- Research data management guidance
- Overview of data protection
-
Electronic Lab Notebooks at The University of Edinburgh – wiki notes/slides
David Girdwood
EDINA & Data Library




 The tenth Research Data Management Forum (RDMF), organised by DCC was held in St Anne’s College, University of Oxford on 3 and 4 September. Thus follows an account of proceedings, the goals of which were to examine aspects of arts and humanities research data that may require a different kind of handling to that given to other disciplines, and to discuss how needs for support, advocacy, training and infrastructure are being met.
The tenth Research Data Management Forum (RDMF), organised by DCC was held in St Anne’s College, University of Oxford on 3 and 4 September. Thus follows an account of proceedings, the goals of which were to examine aspects of arts and humanities research data that may require a different kind of handling to that given to other disciplines, and to discuss how needs for support, advocacy, training and infrastructure are being met.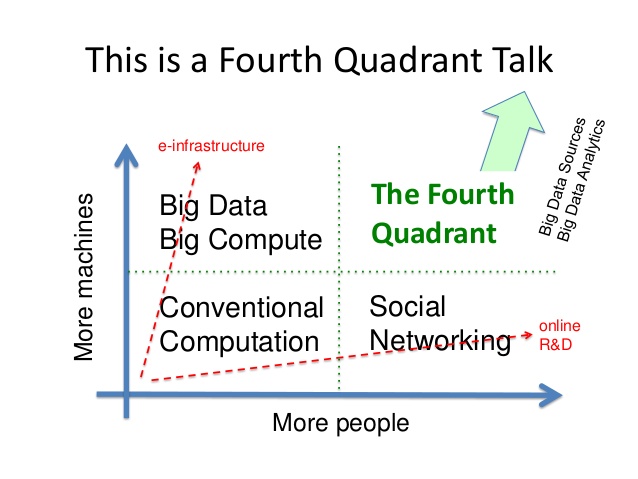 Fig. 1 – From ‘Social Machines’ by Dave De Roure on Slideshare (http://www.slideshare.net/davidderoure/social-machinesgss)
Fig. 1 – From ‘Social Machines’ by Dave De Roure on Slideshare (http://www.slideshare.net/davidderoure/social-machinesgss)

 Paul emphasised the need for the internet to be seen as a social space for SARU researchers. At the moment research is disseminated across multiple private websites without consistent links back to the university. Research objects and documentation is split over multiple platforms (e.g. Soundcloud, Vimeo, YouTube). This makes resource discovery difficult except through individual artists web spaces. As of March 2014 research disseminated across multiple private websites will be linked to/from the university with data stored on
Paul emphasised the need for the internet to be seen as a social space for SARU researchers. At the moment research is disseminated across multiple private websites without consistent links back to the university. Research objects and documentation is split over multiple platforms (e.g. Soundcloud, Vimeo, YouTube). This makes resource discovery difficult except through individual artists web spaces. As of March 2014 research disseminated across multiple private websites will be linked to/from the university with data stored on 