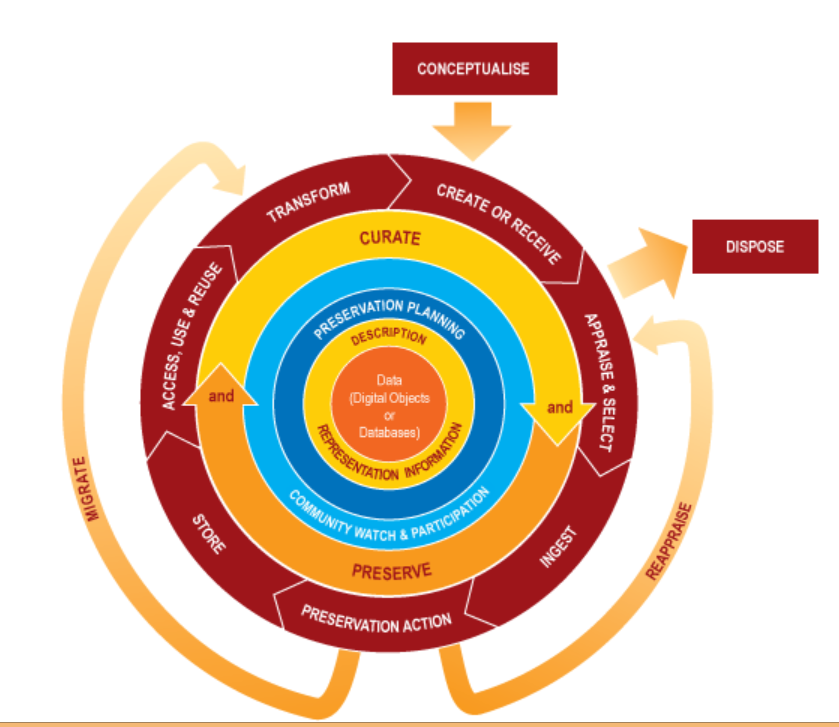
Research published a year ago in the journal Current Biology found that 80 percent of original scientific data obtained through publicly-funded research is lost within two decades of publication. The study, based on 516 random journal articles which purported to make associated data available, found the odds of finding the original data for these papers fell by 17 percent every year after publication, and concluded that “Policies mandating data archiving at publication are clearly needed” (http://dx.doi.org/10.1016/j.cub.2013.11.014).
In this post I’ll touch on three different initiatives aimed at strengthening policies requiring publicly funded data – whether produced by government or academics – to be made open. First, a report published last month by the Research Data Alliance Europe, “The Data Harvest: How sharing research data can yield knowledge, jobs and growth.” Second, a report by an EU-funded research project called RECODE on “Policy Recommendations for Open Access to Research Data”, released last week at their conference in Athens. Third, the upcoming publication of Scotland’s Open Data Strategy, pre-released to attendees of an Open Data and PSI Directive Awareness Raising Workshop Monday in Edinburgh.
Experienced so close together in time (having read the data harvest report on the plane back from Athens in between the two meetings), these discrete recommendations, policies and reports are making me just about believe that 2015 will lead not only to a new world of interactions in which much more research becomes a collaborative and integrative endeavour, playing out the idea of ‘Science 2.0’ or ‘Open Science’, and even that the long-promised ‘knowledge economy’ is actually coalescing, based on new products and services derived from the wealth of (open) data being created and made available.
‘The initial investment is scientific, but the ultimate return is economic and social’
John Wood, currently the Co-Chair of the global Research Data Alliance (RDA) as well as Chair of RDA-Europe, set out the case in his introduction to the Data Harvest report, and from the podium at the RECODE conference, that the new European commissioners and parliamentarians must first of all, not get in the way, and second, almost literally ‘plan the harvest’ for the economic benefits that the significant public investments in data, research and technical infrastructure are bringing.
 The report’s irrepressible argument goes, “Just as the World Wide Web, with all its associated technologies and communications standards, evolved from a scientific network to an economic powerhouse, so we believe the storing, sharing and re-use of scientific data on a massive scale will stimulate great new sources of wealth.” The analogy is certainly helped by the fact that the WWW was invented at a research institute (CERN), by a researcher, for researchers. The web – connecting 2 billion people, according to a McKinsey 2011 report, contributed more to GDP globally than energy or agriculture. The report doesn’t shy away from reminding us and the politicians it targets, that it is the USA rather than Europe that has grabbed the lion’s share of economic benefit– via Internet giants Google, Amazon, eBay, etc. – from the invention of the Web and that we would be foolish to let this happen again.
The report’s irrepressible argument goes, “Just as the World Wide Web, with all its associated technologies and communications standards, evolved from a scientific network to an economic powerhouse, so we believe the storing, sharing and re-use of scientific data on a massive scale will stimulate great new sources of wealth.” The analogy is certainly helped by the fact that the WWW was invented at a research institute (CERN), by a researcher, for researchers. The web – connecting 2 billion people, according to a McKinsey 2011 report, contributed more to GDP globally than energy or agriculture. The report doesn’t shy away from reminding us and the politicians it targets, that it is the USA rather than Europe that has grabbed the lion’s share of economic benefit– via Internet giants Google, Amazon, eBay, etc. – from the invention of the Web and that we would be foolish to let this happen again.
This may be a ruse to convince politicians to continue to pour investment into research and data infrastructure, but if so it is a compelling one. Still, the purpose of the RDA, with its 3,000 members from 96 countries is to further global scientific data sharing, not economies. The report documents what it considers to be a step-change in the nature of scientific endeavour, in discipline after discipline. The report – which is the successor to the 2010 report also chaired by Wood, “Riding the Wave: How Europe can gain from the rising tide of scientific data,” celebrates rather than fears the well-documented data deluge, stating,
“But when data volumes rise so high, something strange and marvellous happens: the nature of science changes.”
The report gives examples of successful European collaborative data projects, mainly but not exclusively in the sciences, such as the following:
- Lifewatch – monitors Europe’s wetlands, providing a single point to collect information on migratory birds. Datasets created help to assess the impact of climate change and agricultural practices on biodiversity
- Pharmacog – partnership of academic institutions and pharmaceutical companies to find promising compounds for Alzheimer’s research to avoid expensive late-stage failures of drugs in development.
- Human Brain Project – multidisciplinary initiative to collect and store data in a standardised and systematic way to facilitate modelling.
- Clarin – integrating archival information from across Europe to make it discoverable and usable through a single portal regardless of language.
The benefits of open data, the report claims, extends to three main groups:
- to citizens, who will benefit indirectly from new products and services and also be empowered to participate in civic society and scientific endeavour (e.g. citizen science);
- to entrepeneurs, who can innovate based on new information that no one organisation has the money or expertise to exploit alone;
- to researchers, for whom the free exchange of data will open up new research and career opportunities, allow crossing of boundaries of disciplines, institutions, countries, and languages, and whose status in society will be enhanced.
‘Open by Default’
If the data harvest report lays out the argument for funding open data and open science, the RECODE policy recommendations focus on what the stakeholders can do to make it a reality. The project is fundamentally a research project which has been producing outputs such as disciplinary case studies in physics, health, bioengineering, environment and archaeology. The researchers have examined what they consider to be four grand challenges for data sharing.
- Stakeholder values and ecosystems: the road towards open access is not perceived in the same way by those funding, creating, disseminating, curating and using data.
- Legal and ethical concerns: unintended secondary uses, misappropriation and commercialization of research data, unequal distribution of scientific results and impacts on academic freedom.
- Infrastructure and technology challenges: heterogeneity and interoperability; accessibility and discoverability; preservation and curation; quality and assessibility; security.
- Institutional challenges: financial support, evaluating and maintaining the quality, value and trustworthiness of research data, training and awareness-raising on opportunities and limitations of open data.
 RECODE gives overarching recommendations as well as stake-holder specific ones, a ‘practical guide for developing policies’ with checklist for the four major stakeholder groups: funders, data managers, research institutions and publishers.
RECODE gives overarching recommendations as well as stake-holder specific ones, a ‘practical guide for developing policies’ with checklist for the four major stakeholder groups: funders, data managers, research institutions and publishers.
‘Open Changes Everything’
The Scottish government event was a pre-release of the open data strategy, which is awaiting final ministerial approval, though in its final draft, following public consultation. The speakers made it clear that Scotland wants to be a leader in this area and drive culture change to achieve it. The policy is driven in part by the G8 countries’ “Open Data Charter” to act by the end of 2015 on a set of five basic principles – for instance, that public data should be open to all “by default” rather than only in special cases, and supported by UK initiatives such as the government-funded Open Data Institute and the grassroots Open Knowledge Foundation.
Improved governance (or public services) and ‘unleashing’ innovation in the economy are the two main themes of both the G8 charter and the Scotland strategy. The fact was not lost on the bureaucrats devising the strategy that public sector organisations have as much to gain as the public and businesses from better availability of government data.
The thorny issue of personal data is not overlooked in the strategy, and a number of important strides have been taken in Scotland by government and (University of Edinburgh) academics recently on both understanding the public’s attitudes, and devising governance strategies for important uses of personal data such as linking patient records with other government records for research.
According to Jane Morgan from the Digital Public Services Division of the Scottish Government, the goal is for citizens to feel ownership of their own data, while opening up “trustworthy uses of data for public benefit.”
Tabitha Stringer, whose title might be properly translated as ‘policy wonk’ for open data, reiterated the three main reason for the government to embrace open data:
- Transparency, accountability, supporting civic engagement
- Designing and delivering public services (and increasingly digital services)
- Basis for innovation, supporting the economy via growth of products & services
‘Digital first’
The remainder of the day focused on the new EU Public Service Information directive and how it is being ‘transposed’ into UK legislation to be completed this year. In short, the Freedom of Information and other legislation is being built upon to require not just publication schemes but also asset lists with particular titles by government agencies. The effect of which, and the reason for the awareness raising workshop is that every government agency is to become a data publisher, and must learn how to manage their data not just for their own use but for public ‘re-users’. Also, for the first time academic libraries and other ‘cultural organisations’ are to be included in the rules, where there is a ‘public task’ in their mission.
‘Digital first’ refers to the charging rules in which only marginal costs (not full recovery) may be passed on, and where information is digital the marginal cost is expected to be zero, so that the vast majority of data will be made freely available.
 Robin Rice
Robin Rice
EDINA and Data Library