The tenth Research Data Management Forum (RDMF), organised by DCC was held in St Anne’s College, University of Oxford on 3 and 4 September. Thus follows an account of proceedings, the goals of which were to examine aspects of arts and humanities research data that may require a different kind of handling to that given to other disciplines, and to discuss how needs for support, advocacy, training and infrastructure are being met.
The tenth Research Data Management Forum (RDMF), organised by DCC was held in St Anne’s College, University of Oxford on 3 and 4 September. Thus follows an account of proceedings, the goals of which were to examine aspects of arts and humanities research data that may require a different kind of handling to that given to other disciplines, and to discuss how needs for support, advocacy, training and infrastructure are being met.
Dave De Roure (Director of the Oxford e-Research Centre) started proceedings as keynote #1. He introduced the concept of the ‘fourth quadrant social machine’ (see Fig. 1) which extends the notion of ‘citizen as scientist’ taking advantage of the emergence of new analytical capabilities, (big) data sources and social networking. He talked also about the ‘End of Theory‘ – the idea that the data deluge is making scientific method obsolete also referencing Douglas Kell’s BioEssay ‘Here is the evidence, now what is the hypothesis‘ which argues that that “data- and technology-driven programmes are not alternatives to hypothesis-led studies in scientific knowledge discovery but are complementary and iterative partners with them.” This he continued, could have major influence on how research is conducted not only in hard sciences but also the arts and humanities.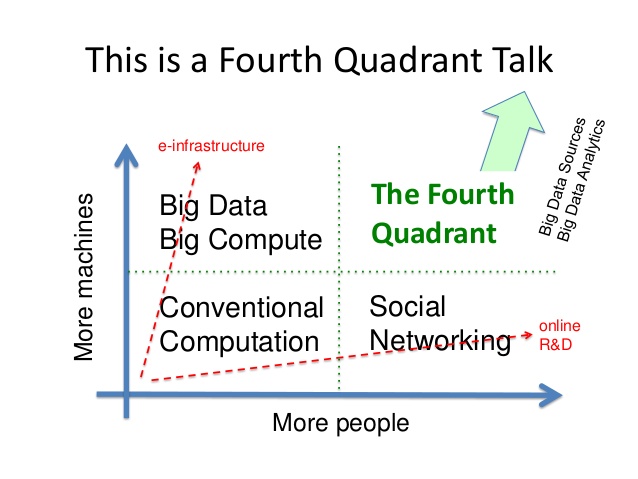 Fig. 1 – From ‘Social Machines’ by Dave De Roure on Slideshare (http://www.slideshare.net/davidderoure/social-machinesgss)
Fig. 1 – From ‘Social Machines’ by Dave De Roure on Slideshare (http://www.slideshare.net/davidderoure/social-machinesgss)
He contends that citizen science initiatives such as Zooniverse (real science online) extend the idea of ‘human as slave to the computer’ however stating that the ‘more we give the computer to do the more we have to keep an eye on what they do.’ De Roure talked about sharing methods being as important as sharing data harnessing the web as lens (e.g. Twitterology) onto society, as infrastructure (e-science/e-research), and as the artifact of study. He went on to highlight innovative sharing initiatives in the arts and humanities that employ new analytical approaches such as:
- the HATHI Trust Research Center which ‘enables computational access for nonprofit and educational users to published works in the public domain now and, in the future’ i.e. take your code to the data and get back your results!
- CLAROS which uses semantic web technologies and image recognition techniques to make the geographically separate scholarly art datasets ‘interoperable’ and accessible to a broad range of users’
- SALAMI (Structural Analysis of Large Amounts of Music Information) which focuses on ‘developing and evaluating practices, frameworks, and tools for the design and construction of worldwide distributed digital music archives and libraries’
De Roure used the phrase ‘from signal to understanding’ to describe the workflow of the ‘social machine’ and went on to described the commonalities that the arts and humanities community have with other disciplines such as working with multiple data sources (often incomplete and born digital), sharing of new and innovative digital methods, the challenges of resource discovery and publication of new digital artifacts, the importance of provenance, and risks of increasing automation. He also highlighted those differences that digital resources in arts and humanities possess in relation to other disciplines in the age of the ‘social machine’ such as specific content types and their relationship to physical artifacts, curated collections and an ‘infinite archive’ of heterogeneous content, publication as both subject and record of research, and the emphasis on multiple interpretations and critical thinking.
Keynote #2 was delivered by Leigh Garrett (Director of the Virtual Arts Data Service) who opined that little is really known about the ‘state’ of research data in the visual arts. It is both tangible yet intangible (what is data in the visual arts?)! Both physical and digital, heterogeneous and infinite, complex and complicated. He made mention of the Jisc-funded KAPTUR project which was aimed to create and pilot a sectoral model of best practice in the management of research data in the visual arts.

As part of the exercise KAPTUR evaluated 12 technical systems most suited for managing research data in the visual arts including CKAN, Figshare, EPrints, DataFlow. Criteria such as user friendliness, visual engagement, flexibility, hosted solution, licensing, versioning, searching were considered. Figshare was seen as user friendly, visually engaging, intuitive,and flexible however the use of CC Zero licences were seen as inappropriate for visual arts research data due to commercial usage clauses. Whilst CKAN appeared most suited no single solution completely fulfilled all requirements of researchers.
Fig 2. Lucie Rie, Sheet of sketches from Council of Industrial Design correspondence for Festival of Britain, 1951. © Mrs. Yvonne Mayer/Crafts Study Centre.
Available from VADS
Simon Willmoth then gave an institutional perspective from the University of the Arts London. It was interesting that from his experience abstract terms such as research data do not engage researchers, and indeed the term is not in common usage by art and design researchers. His definition in the context of art and design was that research data can be ‘considered anything created, captured or collected as an output of funded research work in its original state’. He also observed that as soon as researchers understand RDM concepts they ask for all of their material (past and present) to be digitised! Echoing earlier presentations regarding the ‘heterogeneous and infinite’ nature of research data in the arts and humanities Simon indicated that artists and designers normally have their own websites, some of the content can be regarded as research data e.g. drawings, storyboards, images, whilst some of it is a particular view dependent upon what it is used for at that instant. He then described the institutional challenges of resourcing (staff, storage, time), researcher engagement, curation (incl. legal, ethical and commercial constraints), infrastructure, and enhanced access. Simon finished with some very interesting quotes from researchers regarding how they perceive their work in relation to RDM e.g.
The work that is made is evidence of the journey to the completed artwork …… it’s kind of a continuous archive of imagery
I try not to throw things out but I often cut things up to use as collage material …. so it’s continual construction and deconstruction. Actually ordering is part of my own creative process, so the whole idea of archiving I think is really interesting
I used to think of a website as something where you display things and now increasingly I see it as a way of it recording the process, so I am using more like a Blog structure. But I am happy to post notes, photographs, drawings, observations and let other people see the process
My sketch books tend to be a mish-mash between logging of rushes notes, detailing each shot, things that I read, things that I hear, books that I’m reading, so it will be a jumble of texts but they’ve all gone in to the making of a piece of work.

Simon showcased the Stanley Kubrick Archive based at UAL which contains draft and completed scripts, research materials such as books, magazines and location photographs. It also holds set plans and production documents such as call sheets, shooting schedules, continuity reports and continuity Polaroids. Props, costumes, poster designs, sound tapes and records also feature, alongside publicity press cuttings. He argues that the approach of digital copy and physical artifact accompanied by a web catalogue may be the way forward for RDM in the field of art and design.
Julianne Nyhan (UCL) kicked off day two providing a researcher’s view on arts and humanities data management/sharing with particular emphasis on infrastructure needs and wants. She observed that arts and humanities data are artifacts of human expression, interaction and imagination which tends to be collected rather than generated and rarely by those who create the object(s) which can be:
- complex complete with variants, annotations, editorial comment
- multi-lingual
- long lasting
- studied for many purposes
Julianne also reiterated the need to bridge management and sharing on both physical and digital objects as well as more documentation of interpretative processes and interventions (for which she employs a range of note management tools). She went onto say that much of the work done in her own discipline goes beyond disciplinary/academic/institutional boundaries and that the need to retain and appreciate the bespoke should be balanced against need for standardisation.
In terms of strategic developments Julianne saw much mileage in facilitating more research across linguistic borders (through legal instruments at a national/international level) with resultant access to large multilingual datasets from different cultures to inform comparative and transnational research.
Next up Paul Whitty and Felicity Ford (Oxford Brookes University) provided an overview of RDM practices at the Sonic Art Research Unit (SARU). The use of the internet to advertise work is common amongst SARU researchers, musicians, freelance artists. It was however recognised that there lacked any unified web presence such as Ubuweb.
 Paul emphasised the need for the internet to be seen as a social space for SARU researchers. At the moment research is disseminated across multiple private websites without consistent links back to the university. Research objects and documentation is split over multiple platforms (e.g. Soundcloud, Vimeo, YouTube). This makes resource discovery difficult except through individual artists web spaces. As of March 2014 research disseminated across multiple private websites will be linked to/from the university with data stored on RADAR, the multi-purpose online “resource bank” for Oxford Brookes thus enabling traceability and impact measurement in terms of the use of digital research assets. As a concluding remark Paul did question whether university IT departments were qualified to provide bespoke website design for arts practitioners and researchers.
Paul emphasised the need for the internet to be seen as a social space for SARU researchers. At the moment research is disseminated across multiple private websites without consistent links back to the university. Research objects and documentation is split over multiple platforms (e.g. Soundcloud, Vimeo, YouTube). This makes resource discovery difficult except through individual artists web spaces. As of March 2014 research disseminated across multiple private websites will be linked to/from the university with data stored on RADAR, the multi-purpose online “resource bank” for Oxford Brookes thus enabling traceability and impact measurement in terms of the use of digital research assets. As a concluding remark Paul did question whether university IT departments were qualified to provide bespoke website design for arts practitioners and researchers.
James Wilson, Janet McKnight and Sally Rumsey then gave an overview of the University of Oxford approach to RDM in the humanities which utilises different business models (extensible or reducible) for different components e.g. DataFinder, Databank, DataFlow, DHARMa. Findings from earlier projects at Oxford indicated that humanities research data tends not to depreciate over time unlike that for harder sciences, is difficult to define, tends to be compiled from existing sources and not created from scratch,and is often not in an optimal format for analysis. Other findings indicated that humanities researchers are least likely to conduct their research as part of a team, least likely to be externally funded, least likely to have deposited data in a repository. Conclusions reached were that humanities researchers were amongst the hardest to reach and that training and support is required to encourage cultural change. Janet McKnight from the Digital Humanities Archives for Research Materials (DHARMa) Project then spoke about enabling digital humanities research through effective data preservation warning that before you impose a workflow in terms of developing systems and processes it would be wise to ‘walk a mile in their [the researcher’s] shoes!’
This was a well-attended and enlightening event, ably organised and chaired by Martin Donnelly (DCC). It offered insight and a wide range of perspectives all of which enhance our understanding of service, of practice, of advocacy, of support in relation to research data management in the arts and humanities.
Slides from all presenters are available from DCC website.
Stuart Macdonald
EDINA & Data Library