Home University of Edinburgh Library Essentials
June 26, 2026

New to the Library: The Listener Historical Archive
I’m happy to let you know that after a successful trial earlier this year the Library now has access to The Listener Historical Archive, 1929-1991 from Gale Cengage. This gives you complete access to the archive of this landmark BBC publication.

You can access The Listener Historical Archive, 1929-1991 via the Databases A-Z list and Newspapers & Magazines database list. You can also access the title through DiscoverEd.

Screenshot from front page of first issue, Wednesday, January 16, 1929.
NHS at 70: Explore the history of the NHS through our primary sources
70 years ago today, 5 July, the National Health Service (NHS) was established, one of a number of social and welfare reforms from the post-World War II Labour government (though initial proposals for the NHS came from the World War II coalition government). Launched just over two years after Aneurin Bevan, Minister of Health, published his National Health Service Bill, the NHS provided medical and healthcare services for free at the point of delivery.
On the NHS’s 70th birthday I have pulled together a small selection of primary resources, digital and physical, you have access to at the Library that will help you explore the history of the NHS.
What did the people think?
Mass Observation was a pioneering social research organisation founded in 1937. The aim was to create an ‘anthropology of ourselves’, and by recruiting a team of observers and a panel of volunteer writers they studied the everyday lives of ordinary people in Britain. This original work continued until the early 1950s and gives unparalleled insight into everyday life in Britain during that time.

Through our Library you have access to Mass Observation Online, which makes available the entire Mass Observation archive from that period and includes original manuscript and typescript papers (such as diaries, day reports, questionnaires, observations, etc.) created and collected by the Mass Observation organisation, as well as printed publications, photographs and some interactive features.

Mass-Observation. 1949. Meet Yourself at the Doctor’s. London: Naldrett. Available from Mass Observation Online.
In Mass Observation Online you will find a large amount of material detailing people’s opinions and experiences of the NHS from its earliest days. From Mass Observation’s own file reports and publications pulling together people’s comments, observations and experiences of the NHS to the original diary entries and questionnaire responses.
The material available allows you to read about people’s views on the NHS prior to it being launched and their opinions and experiences of the service in its first few years of existence.
When you are using Mass Observation Online the easiest way to find material regarding the NHS is by clicking on the “Popular Searches” button near the top right-hand side of page and then under the “Organisations” tab click on “National Health Service”. Read More
A Prized Collection
We were recently rather excited to receive a significant accrual to an existing donation of records from Scottish Gymnastics. This includes over 100 books (some of them rare and inscribed), papers and photographs and an extensive collection of shields, trophies, medals, and other artefacts. A donation of objects like these in such a quantity is quite unusual for us and they make up by far the largest part of the Scottish Gymnastics archive. However the proportion of objects to paper records makes complete sense in the context of the organisation’s chief focus on local, national and international competitions.
The collection comprises a real mix of objects, including medals, shields, trophies and plaques, dating from the 1890s (when the organisation was new) right up to 2017. As well as objects which were given as awards, the collection also includes commemorative objects, particularly glassware, which were given to Scottish Gymnastics to mark their participation in particular events over the years.
Probably the most historically notable item in the collection is the Scottish Shield, an impressively decorated three-foot wide object bearing the Scottish Gymnastics logo and the names of the previous winners (picture below):

The shield was awarded as part of an annual competition between Scottish gymnastics clubs. The first winners, in 1890, were the Aberdeen Gymnastic and Rowing Club (the oldest of the Scottish gymnastics clubs). Jim Prestidge’s invaluable book The History of British Gymnastics also features this photograph of the shield in 1902, when it was won by the Dundee Gymnastic and Athletic Club (shield is on the far left).

At the time Prestidge was writing (1988), the Scottish Shield was still being awarded, and Prestidge states that it “is the longest serving Team Shield still in service”. It must certainly be one of the oldest gymnastics awards in Scotland, predating the famous Adams Shield (also featured in the above photograph, on the right) by nine years. We would like to find out more about the history of the Scottish Shield, so please do let us know if you have any information to share!
Artefacts like these form an important part of sporting heritage collections, but because of their unwieldy nature, they are often at risk of being discarded or forgotten, with institutions sometimes being reluctant to take them in. So it’s fantastic to now have this very tangible – and often downright beautiful – part of gymnastics history here at the Centre for Research Collections. The items are a valuable resource for understanding the material culture of gymnastics as well as giving precise information about individual, team and club achievements over time. It would be great to now see researchers begin to use this collection to its full potential.
The Scottish Gymnastics archives catalogue is currently being updated to include these new items. Once this is complete, the catalogue will be viewable here:
http://archives.collections.ed.ac.uk/repositories/2/resources/86677
Clare Button
Project Archivist
Sources
Prestidge, Jim, The History of British Gymnastics (British Amateur Gymnastics Association, 1988)
New to the Library: New York Amsterdam News
I’m delighted to let you know that following a successful trial in 2017/18 the Library has now purchased access to the New York Amsterdam News (1922-1993) from ProQuest Historical Newspapers. Founded in 1909 this is one of the leading Black newspapers of the 20th century and the oldest and largest Black newspaper in New York City.
![]()
You can access New York Amsterdam News (1922-1993) via the Databases A-Z list and Newspapers & Magazines database list. You can also access the title through DiscoverEd*
The Amsterdam News was founded over 100 years ago by James H. Anderson and was named after the street where he lived and where the first issues were produced and sold. It was one of only 50 Black newspapers in the United States at that time. Read More
New! News, Policy & Politics Magazine Archive
I’m happy to let you know that following some successful trials in the last couple of years the Library has purchased the News, Policy & Politics Magazine Archive from ProQuest. This resource offers digital access to the archival runs of 15 major 20th and 21st century consumer magazines covering such fields as the history of politics, current events, public policy and international relations. Central to this collection is the archive of Newsweek, one of the 20th century’s most prominent and highest circulating general interest magazine.

You can access News, Policy & Politics Magazine Archive from the Databases A-Z list and appropriate databases by subject lists. You’ll soon be able to access it from DiscoverEd as well. Read More
New to the Library: Daily Mail Historical Archive
I’m really pleased to let you know that the Library has purchased access to the Daily Mail Historical Archive (1896-2004) from Gale Cengage. Regardless of your personal feelings about the Daily Mail this is a fascinating archive that provides access to over 100 years of the newspaper, while also providing an important alternative perspective to newspapers such at The Times, The Guardian, etc.

You can access Daily Mail Historical Archive (1896-2004) via the Databases A-Z list, Newspapers & Magazines database list and relevant subject guides. Access via DiscoverEd will also become available soon.
The Daily Mail Historical Archive includes nearly 1.2 million pages of content from the paper, including all of the major news stories, features, advertisements and images. And as well as the regular edition of the newspaper, uniquely the archive also includes the Daily Mail Atlantic Edition, which was published on board the transatlantic liners that sailed between New York and Southampton between 1923 and 1931. Issues of the Daily Mail Atlantic Edition are very rare and not available digitally from any other source. Read More
Channel Islands occupation: through the Library’s online primary sources
On this day, 30 June, in 1940 the Germans invaded the Channel Islands which was the beginning of nearly 5 years occupation. In this week’s blog I’m using some of the Library’s online resources to find primary source material to discover more about this facet of the Second World War.
I recently had the opportunity to visit the Jersey War Tunnels, one of Jersey’s many tunnel complexes built by mostly forced and slave labour under German command during the occupation.I have to admit that before that visit I really knew very little about this period in the Channel Islands history but I was inspired by the incredibly moving and fascinating exhibition to try and find out what primary source material was available to us through the University Library’s fantastic online primary source collections about the occupation.

© Mark Cairney
There are many stories that could be told about the Channel Islands occupation and I encourage you to seek them out but due to the nature of our online primary source collections and time limits I’m focusing on what the outside world, mainly Britain, knew (or didn’t) about what was happening on the Channel Islands during the occupation.
The blitzkrieg nears Britain
The first half of 1940 was a dark time for the Allies in the Second World War. In fairly quick succession Denmark, Norway, Belgium, the Netherlands and France were invaded by Germany. With the evacuation at Dunkirk (Operation Dynamo) and France, faced with no real other choice, signing an armistice with Germany in June of that year, Britain was now on its own and under threat.

The Daily Mirror, Tuesday, 18 June 1940, p. 7. UK Press Online. Accessed 25th May 2018.
Marking up collections sites with Schema.org
This blog was written by Holly Coulson, who is working with Nandini Tyagi on this project.
For the last three months, I have been undergoing a Library Metadata internship with the Digital Development team over in Argyle House. Having the opportunity to see behind the scenes into the more technical side of the library, I gained far more programming experience I ever imagined I would, and worked hands on with the collections websites themselves.
Most people’s access to University of Edinburgh’s holdings is primarily through DiscoverEd. But the Collections websites exist as a complete archive of all of the materials that Edinburgh University have, from historical alumni to part of the St Cecilia’s Hall musical instrument collection. These sites are currently going through an upgrade, with new interfaces and front pages.
My role in all of this, along with my fellow intern Nandini, was to analyse and improve how the behind-the-scenes metadata works in the grander scheme of things. As the technological world continually moves towards linked data and the interconnectivity of the Internet, developers are consciously having to update their websites to include more structured data and mark-up. That was our job.
Our primary aim was to implement Schema.org into the collections.ed.ac.uk spaces. Schema, an open access structured data vocabulary, allows for major search engines, such as Google and Yahoo to pull data and understand what it represents. For collections, you can label the title as a ‘schema:name’ and even individual ID numbers as ‘schema:Identifier’. This allows for far more reliable searching, and allows websites to work in conjunction with a standardised system that can be parsed by search engines. This is ultimately with the aim to optimise searches, both in the ed.ac.uk domain, and the larger search engines.
Our first major task was the research. As two interns, both doing our Masters, we had never heard of Schema.org, let alone seen it implemented. We analysed various collections sites around the world, and saw their use of Schema was minimal. Even large sites, such as the Louvre, or the National Gallery, didn’t include any schema within their record pages.
With minimal examples to go off, we decided to just start mapping our metadata inputs to the schema vocabulary, to get a handle on how Schema.org worked in relation to collections. There were some ideas that were very basic, such as title, author, and date. The basics of meta-data was relatively easy to map, and this allowed us to quickly work through the 11 sites that we were focusing on. There were, however, more challenging aspects to the mapping process, which took far longer to figure out. Schema is rather limited for its specific collection framework. While bib.schema exists, an extension that specifically exists for bibliographic information, there is little scope for more specific collection parameters. There were many debates on whether ‘bib.Collection’ or ‘isPartOf’ worked better for describing a collection, and if it was viable to have 4 separate ‘description’ fields, for different variations of abstracts, item descriptions, and other general information.

The initial mappings for /art, showing relatively logical and simple fields

More complicated mappings in /stcecilias, with a lot of repetition and similar fields, and ones that were simply not possible, or weren’t required.
There were other, more specific, fields we had to deal with, that threw up particular problems. The ‘dimensions’ field is always a combined height and width. Schema.org, with regards to specific dimensions, only deals with individual values: a separate height and a separate width value. It wasn’t until we’d mapped everything that we realised this, and had to rethink our mapping. There was also many considerations for if Schema.org was actually required for every piece of metadata. Would linking specific cataloguing and preservation descriptions actually be useful? How often would users actually search for these items? Would using schema.org actually help these fields? We continually had to consider how users actually searched and explored the websites, and whether adding the schema would aid search results. By using a sample of Google Analytics data, we were able to narrow down what should actually be included in the mapping. We ended up with 11 tables, for 11 websites (see above), offering a precise mapping that we could implement straight away.
The next stage was figuring out how to build the schema into the record pages themselves. Much of the Collections website is run on PHP, which takes the information directly from the metadata files and places them in a table when you click on an individual item. Schema.org, in its simplest form, is in HTML, but it would be impossible to go through every single record manually and mark it up. Instead, we had to work with the record configuration files to allow for variables to be tested for schema. If they were a field with a schema definition, the schema.org tag is printed around it, as an automated process. This was further complicated by filters that are used, meaning several sets of code were often required to formulate all the information on the page. As someone who had never worked with PHP before, it was definitely a learning curve. Aided by various courses on search engine optimisation and Google Analytics, we were becoming increasingly confident in our work.
Our first successes were uploading both the /art and /mimed collections schema onto the test servers, only receiving two minimal errors. This proved that our code worked, and that we were returning positive results. By using a handy plugin in Chrome, we were able to see if the code was actually offering readable Schema.org that linked all of our data together.
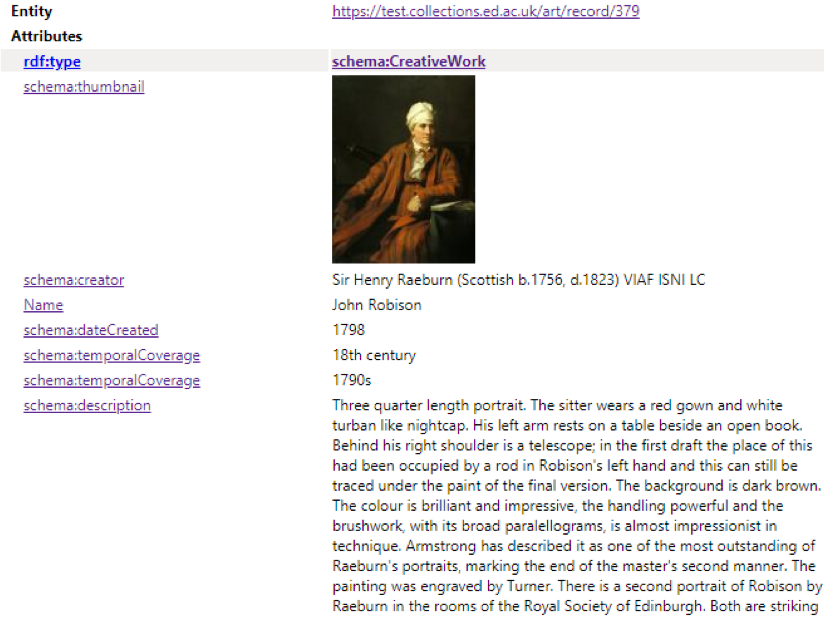
The plugin, OpenLink Structured Data Sniffer, showing the schema and details attributed to the individual record. In this case, Sir Henry Raeburn’s painting of John Robison.
As we come to the final few weeks of our internship, we’ve learnt far more about linked data and search engine optimisation than we imagined. Being able to directly work with the collections websites gave us a greater understanding of how the library works overall. I am personally in the MSc Book History and Material Culture programme, a very hands-on, physical programme, and exploring the technical and digital side of collections has been an amazingly rewarding experience that has aided my studies. Some of our schema.org coding will be rolled out to go live before we finish, and we have realised the possibilities that structured data can bring to library services. We hope we have allowed one more person to find the artwork or musical instrument they were looking for. While time will tell how effective schema.org is in the search results pages, we are confident that we have helped the collections become even more accessible and searchable.
Holly Coulson (Library Digital Development)
Database trials – China Core Newspapers & The Eastern Miscellany
China Core Newspapers provides the full-text articles from 633 current newspapers in China from 2000 onwards. The database is updated daily. The trial can be accessed by going to the China Core Newspapers entry in the Library’s Databases A-Z list, or simply click here. The trial will end on 31 July 2018.

The Eastern Miscellany (《東方雜誌》) was an iconic periodical of the Commercial Press from 1904 to 1948. It is highly regarded as a very important resource for the study of the modern history of China. The database includes the full 44 volumes (819 issues), with over 30,000 articles, 12,000 pictures, and over 14,000 advertisements. Articles cannot be downloaded directly, but the full texts of the articles can be copied and pasted. To access the trial, please click here on the University network. The trial will also be advertised on the Library’s E-resources Trials website. The trial will end on 21 July 2018.
Feedback would be appreciated.
Session Paper Project Internship
My name is Claire and I am the first intern to work with Nicole on the Session Papers Project. I am due to graduate with a master’s degree in paper conservation this year, but I am starting this internship to broaden my knowledge of book conservation. Methods and skills within conservation tend to overlap, and this is especially true with books and paper. My role within this pilot project is to assist in the conservation of 300 books. Conservation treatments include structural repairs, consolidation, and board reattachment. The volumes need to be in a good enough condition to withstand digitisation and further handling following the project.

Claire working in the conservation studio
Collections
 Hill and Adamson Collection: an insight into Edinburgh’s past
My name is Phoebe Kirkland, I am an MSc East Asian Studies student, and for...
Cataloguing the private papers of Archibald Hunter Campbell: A Journey Through Correspondence
My name is Pauline Vincent, I am a student in my last year of a...
Hill and Adamson Collection: an insight into Edinburgh’s past
My name is Phoebe Kirkland, I am an MSc East Asian Studies student, and for...
Cataloguing the private papers of Archibald Hunter Campbell: A Journey Through Correspondence
My name is Pauline Vincent, I am a student in my last year of a...

Projects
Cataloguing the private papers of Archibald Hunter Campbell: A Journey Through Correspondence
My name is Pauline Vincent, I am a student in my last year of a...
Archival Provenance Research Project: Lishan’s Experience
Presentation My name is Lishan Zou, I am a fourth year History and Politics student....