Home University of Edinburgh Library Essentials
June 18, 2026

Thinking about a Data Vault
[Reposted from https://libraryblogs.is.ed.ac.uk/blog/2013/12/20/thinking-about-a-data-vault/]
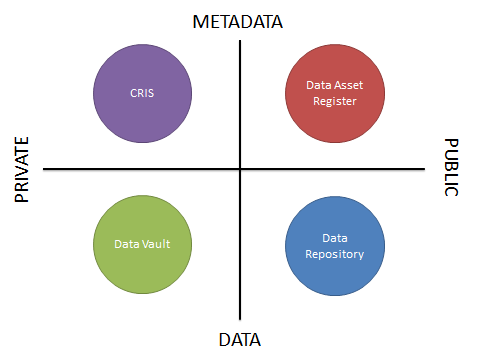
In a recent blog post, we looked at the four quadrants of research data curation systems. This categorised systems that manage or describe research data assets by whether their primary role is to store metadata or data, and whether the information is for private or public use. Four systems were then put into these quadrants. We then started to investigate further the requirements of a Data Asset Register in another blog post.
This blog post will look at the requirements and characteristics of a Data Vault, and how this component fits into the data curation system landscape.
What?
The first aspect to consider is what exactly is a Data Vault? For the purposes of this blog post, we’ll simply consider it is a safe, private, store of data that is only accessible by the data creator or their representative. For simplicity, it could be considered very similar to a safety deposit box within a bank vault. However other than the concept, this analogy starts to break down quite quickly, as we’ll discuss later.
Why?
There are different use cases where a Data Vault would be useful. A few are described here:
- A paper has been published, and according to the research funder’s rules, the data underlying the paper must be made available upon request. It is therefore important to store a date-stamped golden-copy of the data associated with the paper. Even if the author’s own copy of the data is subsequently modified, the data at the point of publication is still available.
- Data containing personal information, perhaps medical records, needs to be stored securely, however the data is ‘complete’ and unlikely to change, yet hasn’t reached the point where it should be deleted.
- Data analysis of a data set has been completed, and the research finished. The data may need to be accessed again, but is unlikely to change, so needn’t be stored in the researcher’s active data store. An example might be a set of completed crystallography analyses, which whilst still useful, will not need to be re-analysed.
- Data is subject to retention rules and must be kept securely for a given period of time.
How?
Clearly the storage characteristics for a Data Vault are different to an open data repository or active data filestore for working data. The following is a list of some of the characteristics a Data Vault will need, or could use:
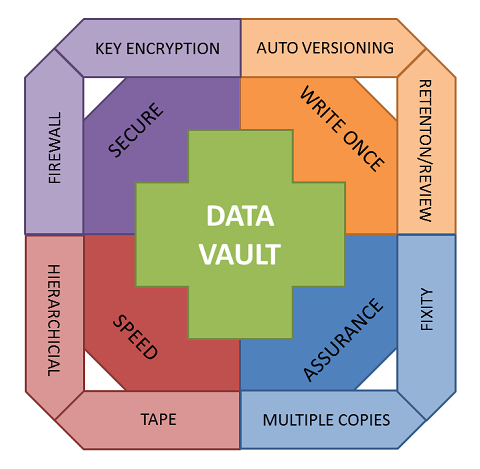
- Write-once file system: The file system should only allow each file to be written once. Deleting a file should require extra effort so that it is hard to remove files.
- Versioning: If the same file needs to be stored again, then rather than overwriting the existing file, it should be stored alongside the file as a new version. This should be an automatic function.
- File security: Only the data owner or their delegate can access the data.
- Storage security: The Data Vault should only be accessible through the local university network, not the wider Internet. This reduces the vectors of attack, which is important given the potential sensitivity of the data contained within the Data Vault.
- Additional security: Encrypt the data, either via key management by the depositors, or within the storage system itself?
- Upload and access: Options include via a web interface (issues with very large files), special shared folders, dedicated upload facilities (e.g. GridFTP), or an API for integration with automated workflows.
- Integration: How would the Data Vault integrate with the Data Asset Register? Could the register be the main user interface for accessing the Data Vault?
- Description: What level of description, or metadata, is required for data sets stored in the Data Vault, to ensure that they can be found and understood in the future?
- Assurance: Facilities to ensure that the file uploaded by the researcher is intact and correct when it reaches the vault, and periodic checks to ensure that the file has not become corrupted. What about more active preservation functions, including file format migration to keep files up to date (e.g. convert Word 95 documents to Word 2013 format)?
- Speed: Can the file system be much slower, perhaps a Hierarchical Storage Management (HSM) system that stores frequently accessed data on disk, but relegates older or less frequently accessed data to slower storage mechanisms such as tape? Access might then be slow (it takes a few minutes for the data to be automatically retrieved from the tape) but the cost of the service is much lower.
- Allocation: How much allocation should each person be given, or should it be unrestricted so as to encourage use? What about costing for additional space? Costings may be hard, because if the data is to be kept for perpetuity, then whole-life costing will be needed. If allocation is free, how to stop it being used for routine backups of data rather than golden-copy data?
- Who: Who is allowed access to the Data Vault to store data?
- Review periods: How to remind data owners what data they have in the Data Vault so that they can review their holdings, and remove unneeded data?
Feedback on these issues and discussion points are very welcome! We will keep this blog updated with further updates as these services develop.
Image available from http://dx.doi.org/10.6084/m9.figshare.873617
Tony Weir, Head of Unix Section, IT Infrastructure
Stuart Lewis, Head of Research and Learning Services, Library & University Collections.
Thinking about a Data Vault
In a recent blog post, we looked at the four quadrants of research data curation systems. This categorised systems that manage or describe research data assets by whether their primary role is store metadata or data, and whether the information is for private or public use. Four systems were then put into these quadrants. We then started to investigate further the requirements of a Data Asset Register in another blog post.
This blog post will look at the requirements and characteristics of a Data Vault, and how this component fits into the data curation system landscape.
What?
The first aspect to consider is what exactly is a Data Vault? For the purposes of this blog post, we’ll simply consider it is a safe, private, store of data that is only accessible by the data creator or their representative. For simplicity, it could be considered very similar to a safety deposit box within a bank vault. However other than the concept, this analogy starts to break down quite quickly, as we’ll discuss later.
Why?
There are different use cases where a Data Vault would be useful. A few are described here:
- A paper has been published, and according to the research funder’s rules, the data underlying the paper must be made available upon request. It is therefore important to store a date-stamped golden-copy of the data associated with the paper. Even if the author’s own copy of the data is subsequently modified, the data at the point of publication is still available.
- Data containing personal information, perhaps medical records, needs to be stored securely, however the data is ‘complete’ and unlikely to change, yet hasn’t reached the point where it should be deleted.
- Data analysis of a data set has been completed, and the research finished. The data may need to be accessed again, but is unlikely to change, so needn’t be stored in the researcher’s active data store. An example might be a set of completed crystallography analyses, which whilst still useful, will not need to be re-analysed.
- Data is subject to retention rules and must be kept securely for a given period of time.
How?
Clearly the storage characteristics for a Data Vault are different to an open data repository or active data filestore for working data. The following is a list of some of the characteristics a Data Vault will need, or could use:
- Write-once file system: The file system should only allow each file to be written once. Deleting a file should require extra effort so that it is hard to remove files.
- Versioning: If the same file needs to be stored again, then rather than overwriting the existing file, it should be stored alongside the file as a new version. This should be an automatic function.
- File security: Only the data owner or their delegate can access the data.
- Storage security: The Data Vault should only be accessible through the local university network, not the wider Internet. This reduces the vectors of attack, which is important given the potential sensitivity of the data contained within the Data Vault.
- Additional security: Do we encrypt the data, either via key management by the depositors, or within the storage system itself.
- Upload and access: Options include via a web interface (issues with very large files), special shared folders, dedicated upload facilities (e.g. GridFTP), or an API for integration with automated workflows.
- Integration: How would the Data Vault integrate with the Data Asset Register? Could the register be the main user interface for accessing the Data Vault?
- Description: What level of description, or metadata, is required for data sets stored in the Data Vault, to ensure that they can be found and understood in the future?
- Assurance: Facilities to ensure that the file uploaded by the researcher is intact and correct when it reaches the vault, and periodic checks to ensure that the file has not become corrupted. What about more active preservation functions, including file format migration to keep files up to date (e.g. convert Word 95 documents to Word 2013 format)
- Speed: Can the file system be much slower, perhaps a Hierarchical Storage Management (HSM) system that stores frequently access data on disk, but relegates older or less frequently access data to slower storage mechanisms such as tape. Access might then be slow (it takes a few minutes for the data to be automatically retrieved from the tape) but the cost of the service is much lower.
- Allocation: How much allocation should each person be given, or should it be unrestricted so as to encourage use? What about costing for additional space? Costings may be hard, because if the data is to be kept for perpetuity, then whole-life costing will be needed. If allocation is free, how to stop it being used for routine backups of data rather than golden-copy data?
- Who: Who is allowed access to the Data Vault to store data?
- Review periods: How to remind data owners what data they have in the Data Vault so that they can review their holdings, and remove unneeded data.
Feedback on these issues and discussion points are very welcome! We will keep this blog updated with further updates as these services develop.
Image available from http://dx.doi.org/10.6084/m9.figshare.873617
Tony Weir, Head of Unix Section, IT Infrastructure
Stuart Lewis, Head of Research and Learning Services, Library & University Collections.
A few of my favourite [festive!] things
At the start of the festive period, I had the best of intentions to post a festive blog post for every day of advent. Alas, there isn’t much mention of Christmas in Thomson’s papers – even his family photo albums are a decidedly festive free zone! However, having three working days left until we break up for the festive period, I thought I would share (you’ve guessed it!) three festive items from the collection…
1) Christmas card to Thomson from his students…


Quite possibly the best Christmas card I’ve ever come across – spelling ‘Christmas’ in mathematical terms. Genius! And if that wasn’t zany enough, there is a wonderfully nebulous poem on the inside!
In all seriousness, this is one of my favourite items in the collection – it is signed by 13 of Thomson’s students, who were obviously very fond of him, and I bet the master of Factorial Analysis loved it!
2) Christmas card from Andromache


Andromache was the wife of Thomson’s son, Hector. Hector was a classicist, so the mythical love story of Hector and Andromache would have been one familiar to him. She is a frequent character in the collection, and is mentioned throughout Thomson’s correspondence by friends and family – Thomson and Lady Thomson appear to have been particularly fond of her. The card depicts her native Cyprus.
3) A Christmas gift from Lady Thomson:


The gift is a thoughtful one – Thomson was brought up near Newcastle, and the sights in this book would have been familiar to him. The book has clearly been well loved and frequently referred to, and has some beautiful images of Newcastle.


With that, I’d like to wish you all a lovely Christmas and a productive New Year!
If anyone recognises their signature or that of anyone else’s on the card, do please get in touch (Emma.Anthony@ed.ac.uk)
REF 2014 Physical Submission
The Research Excellence Framework (REF) is a system for assessing the quality of research in UK HEIs. It replaced the Research Assessment Exercise (RAE) and is undertaken by the four UK higher education funding bodies, to:
– inform the selective allocation of research funding to HEIs
– provide benchmarking information and establish reputational yardsticks
– provide accountability for public investment in research and demonstrate its benefits
The library’s role in the REF submission was to provide overall leadership for the submission of REF2 data and physical outputs; this involved metadata verification of over 7000 records, checking Scopus citation information and the submission of physical research outputs which amounted to almost 700 items including books, portfolios, journals and compositions.
The electronic submission deadline was 29 November 2013 so for most people involved in REF2014 their part was done, however here in the library there were almost 700 physical items still to be submitted and each one of these had to be checked, labelled and boxed up before being sent to HEFCE.
On 12 December the physical outputs left the library on their way to HEFCE, the past few months have been extremely busy here within Scholarly Communications and we are grateful for all the help we’ve received from our acquisitions and cataloguing colleagues in helping us meet this deadline, finally we can breathe a sigh of relief!


Merry Fishmas to you all!
As it’s only a week to go until Christmas, enjoy a festive edition of The Wee Red Herring from the ECA archive, complete with zombies and everything.

December 2009 issue

A festive tale, with zombies.
Photographing The Apocalypse Circa 1483
Recently the Digital Imaging Unit were asked to photograph all 8 illustrations from the book of the Apocalypse in Anton Koberger’s German Bible of 1483. Shelf-mark Inc.45.2. I have selected a few details from the illustrations here to demonstrate the quality of the line and its powerful descriptive impact. ” Koberger was the godfather of Albrecht Dürer, whose family lived on the same street. In the year before Dürer’s birth in 1471.” Giulia Bartrum, Albrecht Dürer and his Legacy, British Museum Press, 2002, pp 94-96, ISBN 0-7141-2633-0
Malcolm Brown




Art Collections at the Edinburgh College of Art Sculpture Party
 Zane by Isobel Turley
Zane by Isobel Turley
The annual Sculpture Party is part of ECA legend. Organised by the Sculpture department, it raises money for the School of Art Degree shows and takes over most of the area surrounding the Sculpture Court. Above is Zane by Isobel Turley, which was one of our acquisitions from the 2013 ECA Degree Show, and was projected in one of the studio spaces used in the party. Below is Winged Victory, looking like she is getting set up for a DJ set. Of course, us in Collections are far too well behaved to attend a riotous party like this, so thanks to Emma Smith for the pictures.

South Asianist celebrates a century of Indian Cinema
The fifth issue of The South Asianist celebrates a century of India cinema with an impressive range of articles, interviews and film reviews.
Senior Indian film-music critic, writer and commentator, Rajiv Vijayakar provides a valuable overview to ‘the role of a song in a Hindi film’ alongside a who’s who of eight decades of Hindi film music.
Founder editor of Stardust and pioneer of film journalism in India, Nari Hira, shares the inside drama behind some of the biggest Bollywood scoops of all time.
While Rajani Krishnakumar, investigates how the nature of the clothing of a heroine and its attributes contribute to the marriage-worthiness of a Tamil woman, using examples from a century of Tamil cinema.
There is also a candid interview with Sai Paranjpye, ‘Queen of humour’ and Ram Mohan, the forgotten ‘father of Indian animation’.
http://www.southasianist.ed.ac.uk

The South Asianist is supported by the University’s Journal Hosting Service: http://journals.ed.ac.uk
Dollymania – Seven Days that Shook the World

1997 was quite a significant year for the Roslin Institute with “’Dolly, the sheep, ‘…the first mammal cloned from a cell from an adult animal…generated an amazing amount of interest from the world’s media.” (Griffin, Harry. ‘Dollymania’, University of Edinburgh Journal, XXXVIII: 2, December 1997, GB237 Coll-1362/4/1476). And so, it’s been exciting to find articles in the offprints discussing her and the issues of cloning, biotechnology, ethics – Dr. Grahame Bulfield even wrote a report to Parliament on what this breakthrough means for science!
Harry Griffin, former Assistant Director (Science) at the Roslin Institute in 1997’s article, ‘Dollymania’ (cited above) provides an insider’s point of view of how Dolly was produced and the science and research involved. He writes,
Dolly was produced from cells that had been taken from the udder of a 6-year old Finn Dorset ewe and cultured for several weeks in the laboratory. Individual cells were then fused with unfertilised eggs from which the genetic material had been removed and 29 of these ‘reconstructed’ eggs – each now with a diploid nucleus from the adult animal – were implanted in surrogate Blackface ewes. One gave rise to a live lamb, Dolly, some 148 days later. Other cloned lambs were derived in the same way by nuclear transfer from cells taken from embryonic and foetal tissue.
…
On Monday, Dolly provided the lead story in most of the papers and Roslin Institute was besieged by reporters and TV crews from all over the world…. Dolly rapidly became the most photographed sheep of all time and was invited to appear on a chat show in the US. Astrologers asked for her date of birth and PPL’s share price rose sharply. President Bill Clinton called on his bioethics’ commission to report on the ethical implications within 90 days and Ian Wilmut was invited to testify to both the UK House of Commons and the US Congress…. Dolly Parton sad she was ‘honoured’ that we have named our progeny after her and that there is no such thing as ‘baaaaaed publicity’. Sadly, we also received a handful of requests to resurrect relatives and loved pets.
 In the article, ‘Seven days that shook the world’ by Harry Griffin and Ian Wilmut in New Scientist, 22 March 1997 also describe the reality of the science of cloning in the face of intense media speculation and reportage.
In the article, ‘Seven days that shook the world’ by Harry Griffin and Ian Wilmut in New Scientist, 22 March 1997 also describe the reality of the science of cloning in the face of intense media speculation and reportage.
Dr. Grahame Bulfield, former Director of the Roslin Institute, wrote several articles in 1997 on biotechnology, ethics, livestock and cloning. In some articles, he writes generally on the techniques of genetic engineering, genome analysis, and embryo manipulations and provides a biological context of these new technologies. (GB237 Coll-1362/4/1394 – 1400). He discusses Dolly more directly in the article, ‘Dit is pas het begin’ in the Dutch journal Natuur & Techniek, No. 8, 1997 (4/1376)  and The Roslin Institute and Cloning an address to the Parliamentary and Scientific Committee in Science in Parliament, Vol. 54, No. 5, September/October 1997 (4/1400). In this particular article he writes specifically about Dolly:
and The Roslin Institute and Cloning an address to the Parliamentary and Scientific Committee in Science in Parliament, Vol. 54, No. 5, September/October 1997 (4/1400). In this particular article he writes specifically about Dolly:
As you know we have been thrown into the middle of public debate recently with a considerable amount of public interest and concern about “Dolly”.  Over a period of about five days we had 3,000 telephone calls, 17 TV crews and we basically ground to a halt. We are perfectly aware now of the issues that are raised , and I don’t believe that a scientific organisation like ours can do anything buy try and be proactive in terms of communicating new biotechnology advances to the public and Government and ensuring the issues involved are widely debated.
Over a period of about five days we had 3,000 telephone calls, 17 TV crews and we basically ground to a halt. We are perfectly aware now of the issues that are raised , and I don’t believe that a scientific organisation like ours can do anything buy try and be proactive in terms of communicating new biotechnology advances to the public and Government and ensuring the issues involved are widely debated.
Thinking about Research Data Asset Registers
[Reposted from https://libraryblogs.is.ed.ac.uk/blog/2013/12/12/thinking-about-research-data-asset-registers/]
In my last blog post, I looked at the four quadrants of research data curation systems. This categorised systems that manage or describe research data assets by whether their primary role is to store metadata or data, and whether the information is for private or public use. Four systems were then put into these quadrants.
The University of Edinburgh already has two active services from this diagram: PURE, our Current Research Information System and DataShare, our open data repository.
This blog post will start to unpack some of the requirements for a Data Asset Register.
The first aspect to cover is its name. What should it be called? Traditionally systems like this, which only hold metadata records that either just describe, or describe and point to other resources, are known as registers, catalogues, directories, indexes, or inventories.
The University already has a ‘Data Catalogue’, maintained by the Data Library. However this list has a different purpose, to hold details of external data. Oxford University, instead of opting for a name such as this, have instead opted to call their service by the verb ‘find’ – DataFinder. Whilst there may be some brand or service name applied to the system we create at the University of Edinburgh, for now its working title is ‘Data Asset Register’ as one of its main functions will be to allow data creators to ‘register’ their data assets by describing them, and if the data is published online to link to the data.
But what should the Data Asset Register provide? The following diagram shows some early thoughts:
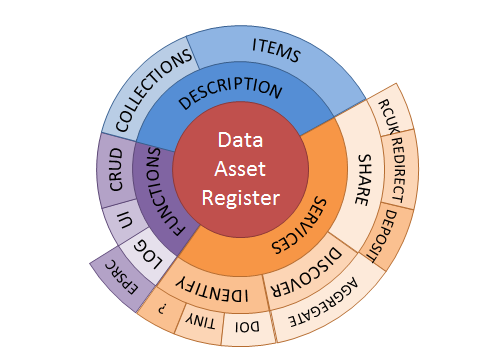
The diagram splits this up into three broad areas:
- Description – what the asset register should describe
- Functions – the functions needed to allow data asset description
- Services – the value-added services that will add benefit to people who register their data
Description
The core purpose of the system is to describe data. This is split into two categories: being able to describe single items or data assets, and describing collections of data assets. Many data assets are created on their own, for example a population health longitudinal study. As such, this should be described on its own. In contrast, some data are created in large sets, where it isn’t necessarily useful to describe every part of that set on its own. In this case, the collection as a whole can be described. A good example of this is the Research Data Australia service from the Australian National Data Service.
We’ll need to decide how to describe the data. A likely initial candidate will be the DataCite Metadata Schema, but we may find this needs to be extended to cover extra elements relevant to the University or the discipline of the data asset being described. There will also be requirements coming from a possible UK research data registry, development of which is being led by the Digital Curation Centre.
Functions
In order to enable data asset description, a register will need certain functions. So far three have been identified:
- CRUD: Create / Read / Update / Delete are the basic functions required when manipulating data. The system should allow records of research data to be created, read later, updated, and if needed, deleted.
- User Interface (UI): In order to enable CRUD functionality, a user interface will be required. To be useful, this will need to provide search and display functionality, for example using faceted search and browse.
- Log: Some funders have requirements to keep data for certain lengths of time, or for periods of time that must be reset each time a data set is accessed. For this reason each access of a data asset must be logged by the system. An example is from the EPSRC:
“Research organisations will ensure that EPSRC-funded research data is securely preserved for a minimum of 10-years from the date that any researcher ‘privileged access’ period expires or, if others have accessed the data, from last date on which access to the data was requested by a third party;”
It may also be that the Data Asset Register can be a front-end for our Data Vault too – more about that in another blog post!
Services
Extra value-added services are required in order to make the Data Asset Register useful to people. Our initial thoughts about these services include the following:
- Identify: The ability to assign identifiers to data assets. Some of these identifiers will need to be persistent.
- DOI: DataCite DOIs allow DOIs to be assigned to data assets, in the same way that DOIs are assigned to journal articles. This allows them to be persistently identified over time even if they move between systems, but also allow them to be cited using a well-known identifier.
- TinyURL: A short URL such as those provided by TinyURL or bitly are useful to give easy web identifiers to objects. For example it might be nice to be able to issue URLs such as http://data.ed.ac.uk/abcd.
- Other: Are there any other identifier systems that we should consider using?
- Discover: It is important that the data records held in the Data Asset Register are searchable and can be indexed by external services. This may be by national, international, or discipline-based data aggregators, or by normal web search engines.
- Share: Whilst often the data assets will be described online but kept offline by the researcher, they may wish to share the data. The Data Asset Register may need to facilitate this in a number of ways:
- Deposit: If the data is held in the Data Vault, along with a description in the Data Asset Register, then using a deposit protocol such as SWORD it would be possible to deposit the data into the institutional data repository, or into an external repository. The Data Asset Register can then record the identifier for the hosted data set.
- Redirect: Where the data is hosted online elsewhere, the Data Asset Register could automatically redirect users. For example visiting http://data.ed.ac.uk/abcd could redirect a visitor directly to the repository, rather than showing them just the data asset record description. If the data is not shared openly, then contact details can be provided of the data owner.
- RCUK: Some funders, such as the RCUK members (Research Councils UK) require funded journal papers to include “a statement on how the underlying research materials – such as data, samples or models – can be accessed”. The data asset register could facilitate this by automatically writing statements such as “Details about accessing the data referenced in this paper may be found at http://data.ed.ac.uk/abcd”
It is very early days in our thinking about what features a Data Asset Register should offer, and like many components of a modern research data management infrastructure, there are very few existing examples to look at. Our thoughts will be refined over the coming months so that we can start looking at implementation options. Is there an existing system that can do all of this for us, or is it better to build something new, either alone or with collaborators?
Images available from http://dx.doi.org/10.6084/m9.figshare.873617
Stuart Lewis, Head of Research and Learning Services, Library & University Collections.
Collections
 Hill and Adamson Collection: an insight into Edinburgh’s past
My name is Phoebe Kirkland, I am an MSc East Asian Studies student, and for...
Cataloguing the private papers of Archibald Hunter Campbell: A Journey Through Correspondence
My name is Pauline Vincent, I am a student in my last year of a...
Hill and Adamson Collection: an insight into Edinburgh’s past
My name is Phoebe Kirkland, I am an MSc East Asian Studies student, and for...
Cataloguing the private papers of Archibald Hunter Campbell: A Journey Through Correspondence
My name is Pauline Vincent, I am a student in my last year of a...

Projects
Cataloguing the private papers of Archibald Hunter Campbell: A Journey Through Correspondence
My name is Pauline Vincent, I am a student in my last year of a...
Archival Provenance Research Project: Lishan’s Experience
Presentation My name is Lishan Zou, I am a fourth year History and Politics student....