Home University of Edinburgh Library Essentials
March 28, 2026

The four quadrants of Research Data Curation Systems
Posted on December 6, 2013 | in Featured, Library, Library & University Collections | by Stuart LewisThe University of Edinburgh, like many other universities, is currently undertaking extensive work to build infrastructure that supports and enables good practice in the area of Research Data Management. This infrastructure ranges from large-scale research storage facilities to data management planning tools.
One aspect of Research Data Management highlighted in the University’s RDM Roadmap is ‘Data stewardship: tools and services to aid in the description, deposit, and continuity of access to completed research data outputs.’
To help describe how these systems fit together yet how they differ from each other, I use a model with two axes to differentiate what they hold, and who can access them. The first axis is used to differentiate between systems that hold only metadata from those that hold files (typically with some level of metadata), while the second differentiates between private systems and public systems.
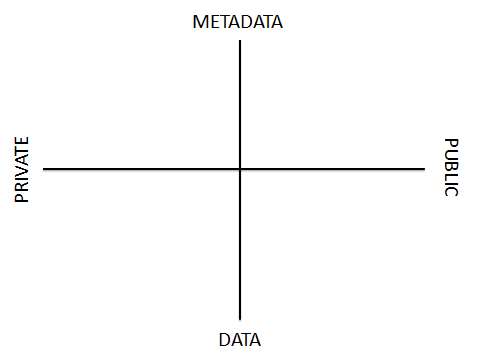
Research information and data management and associated systems aren’t a new phenomenon. We have been offering services in these areas for some time. To demonstrate this, we have two existing systems that provide services in two of the areas:
- PURE is our Current Research Information System (CRIS). It is a private system for the University to record the research outputs it generates. It therefore falls into the metadata / private quadrant. (It can hold files, and has a public interface, but this is primarily for Open Access publications rather than research data).
- DataShare is our open research data repository. It holds and curates data (and associated metadata) for public consumption on behalf of the data creators. It therefore falls into the data / public quadrant.
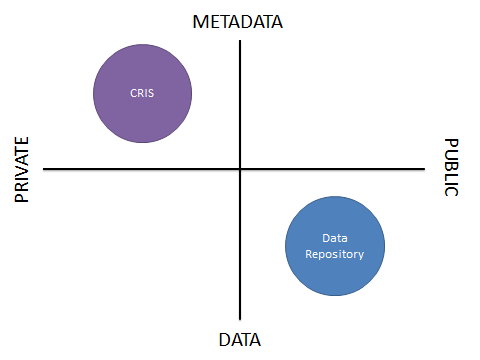
What about the other two quadrants? Are there systems or infrastructure needed to fill these? Is there a case where we need a public store of metadata about research data, or a private store of finished data sets?
The rest of this blog post will argue that there is a need for these, and will describe two pieces of infrastructure that could fill them. Further blog posts will be written that start to unpick the requirements of these systems in more depth.
Public Metadata: Not only is it good practice for a research institution to know what research data it is creating, some research funders require us to do so. In addition the University’s RDM policy requires
“Any data which is retained elsewhere, for example in an international data service or domain repository should be registered with the University.”
The following is an extract from the EPSRC’s expectations for research data management:
“Research organisations will ensure that appropriately structured metadata describing the research data they hold is published (normally within 12 months of the data being generated) and made freely accessible on the internet; in each case the metadata must be sufficient to allow others to understand what research data exists, why, when and how it was generated, and how to access it. Where the research data referred to in the metadata is a digital object it is expected that the metadata will include use of a robust digital object identifier (For example as available through the DataCite organisation – http://datacite.org/).”
This need can be fulfilled by the creation of a Data Asset Register.
Private Data: Whilst some data will be suitable for public sharing, for various reasons some will not, or will need to have access controlled by the data creator. Therefore there is a need for a safe place for keeping data that will be kept secure, both in terms of access and change. Once lodged/archived there, files should only be accessible by the data creator or data manager, and it should not be possible to change files, but only to create newer versions or to remove/delete them.
This need can be fulfilled by the creation of a Data Vault.
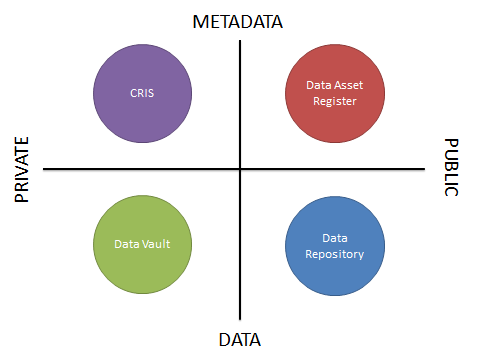
Systems however do not live in isolation, and become more powerful, more useful, and more likely to be used if they are able to integrate with each other. With the ever-growing number of ‘systems’ provided by a large research-intensive university, the last thing that a research data management programme wants to do is to introduce further systems that need to be fed with duplicate information. This means that some or all of the components will need to be integrated together.
There are three obvious integrations between these systems, as shown below:
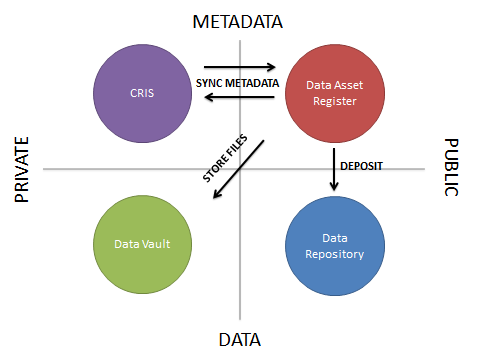
First, because PURE is the master system for holding data and relationships about research outputs (THIS grant, funded THAT piece of equipment, which was used to create THIS data set, that was described in THESE journal articles), records of data sets need to exist within it. However if some or all of these are being created in the Data Asset Register, then they will need to be pushed into PURE. Equally if some data are being registered directly in PURE, it will be useful to pull this out of PURE and into the Data Asset Register.
Secondly, because the Data Asset Register may become the main user interface for entering details of data sets, it could also be the main administrative user interface for uploading files into the Data Vault. If that is the case, then the Data Asset Register and the Vault will need to be integrated.
Finally, for instances where metadata is held in the Data Asset Register, corresponding files are held in the Data Vault, and the data owner decides to make the data openly available, then the Data Asset Register should be able to deposit these as a new item in the Data Repository.
The next challenge will be to describe the requirements for the Data Vault and Data Asset Register. We have some early thoughts about this, and will share these in future blog.
Images available from http://dx.doi.org/10.6084/m9.figshare.873617
Collections
 Hill and Adamson Collection: an insight into Edinburgh’s past
My name is Phoebe Kirkland, I am an MSc East Asian Studies student, and for...
Cataloguing the private papers of Archibald Hunter Campbell: A Journey Through Correspondence
My name is Pauline Vincent, I am a student in my last year of a...
Hill and Adamson Collection: an insight into Edinburgh’s past
My name is Phoebe Kirkland, I am an MSc East Asian Studies student, and for...
Cataloguing the private papers of Archibald Hunter Campbell: A Journey Through Correspondence
My name is Pauline Vincent, I am a student in my last year of a...

Projects
Cataloguing the private papers of Archibald Hunter Campbell: A Journey Through Correspondence
My name is Pauline Vincent, I am a student in my last year of a...
Archival Provenance Research Project: Lishan’s Experience
Presentation My name is Lishan Zou, I am a fourth year History and Politics student....