Jointly with the National Library of Scotland, the University hosted the annual IIIF Showcase and Working Meeting from December 3-6. As consortial members, it was a good opportunity for both institutions to raise their profile within this fast-growing community, and for delegates from all over the world to see Edinburgh in winter while making the most of face-to-face discussions regarding recent developments and the future direction of the framework.
The Showcase took place in the Royal Society of Edinburgh, and this reasonably light-touch session offered an introduction to the concepts and tools and for the host institutions to talk about what they’ve produced so far. It was also IIIF’s new managing director Josh Hadro’s first week in the job: a great way for him to see the community in action! The afternoon saw candidates repair to the NLS and Main Library for breakout sessions in key content areas (Archives, Museums, Digital Scholarship) as well as deeply technical and ‘getting started’ sessions. To finish, everyone then made for St Cecilia’s Hall for a round-up of the day; this was an appropriate setting, as we’ve employed IIIF in the museum’s corresponding collections site.
The Working Group meeting ran over the succeeding three days, in the ECCI and Main Library. This was a smaller undertaking than the Showcase, but it still attracted 70 delegates. There were some really meaty discussions about the direction of the framework: cookbooks and use cases; updates to the Mirador viewer; enhancing the APIs and registries (including more work on authentication and various types of search), and looking at the amazing potential of 3D and AV (e.g. subtitle support, musical notation written as a piece plays), which is something we at the University are well placed to start work on. Discussions about the direction of the community and outreach group took place, as well; this session was led by our (until very recently) very own Claire Knowles, now Assistant Director at Leeds University Library. The first meeting of the Technical Review Committee, which rubber-stamps the specs, took place at the event too, in the huge Dining Room at Teviot.
With increasing engagement across the industry, IIIF’s future looks very bright indeed.
Thanks to everyone that helped out over the week, with a particularly big round of applause to IIIF’s Technical Co-ordinator Glen Robson, who is well-known to many people in the Library due to his previous incarnation as Development Manager at the National Library of Wales.
To (self-indulgently) end the post, here is a little hi-res illustration of the work that we have done at Edinburgh with IIIF.
This is heavily annotated! If you click the speech bubbles, you will turn on annotations, some of which link out to relevant websites (links have a dotted line under the text). Also, the Mirador viewer does comparison very well, so if you
click the four-square icon in the top left
select ‘Add Slot Right’
click ‘Add Item’
double click the manifest (‘IIIF Highlights…’)
select the right image
…you can see the previous version of this picture to see where improvements were made. All of this will go better if you make it full-screen!
This blog was written by Nandini Tyagi, who was working with Holly Coulson on this project.
This blog follows the blog post written by Holly Coulson, my fellow intern at the Library Metadata internship with the Digital Development team at Argyle House. For the benefit of those who are directly reading the second blog, I’ll quickly recap what the project was about. The Library Digital Development team have built a number of data‐driven websites to surface the collections content over the past four years; the sites cover a range of disciplines, from Art to Collections Level Descriptions, Musical Instruments to Online Exhibitions. While they work with metadata standards (Spectrum and Dublin Core), and accepted retrieval frameworks (SOLR indices), they are not particularly rich in a semantic sense, and they do not benefit from advances in browser ‘awareness’; specifically, they do not use linked data. The goal of the project was to embed schema.org metadata within the online records of items within Library and University Collections to bring an aspect of linked data into the site’s functionality, and resultantly, increase the sites’ discoverability through generic search engines (Google etc.) and, more locally, the University’s own website search (Funnelback).
In this blog, I’ll share my experience from the implementation perspective i.e. how were the documented mappings translated into action and what are the key findings from this project. Before I dive into implementation of Schema, it is important to know what Schema is and how does it benefit us. Schema.org is a collaborative, community activity with a mission to create, maintain, and promote schemas for structured data on the Internet, on web pages, in email messages, and beyond. Schema.org vocabulary can be used with many different encodings, including RDFa, Microdata and JSON-LD. These vocabularies cover entities, relationships between entities and actions, and can easily be extended through a well-documented extension model. I’ll explain the need for Schema better through an example. Most webmasters are familiar with HTML tags on their pages. Usually, HTML tags tell the browser how to display the information included in the tag. For example, <h1>Titanic</h1> tells the browser to display the text string “Titanic” in a heading 1 format. However, the HTML tag doesn’t give any information about what that text string means—” Titanic” could refer to the hugely successful movie, or it could refer to the name of a ship—and this can make it more difficult for search engines to intelligently display relevant content to a user. In the collections for example, when the search engine would be crawling the pages, they will not understand if a certain title refers to a painting, sculpture or an instrument. Using Schema, we can help the search engine make sense of the information on the webpage and it can list our website at a higher rank for the relevant queries.
Before: No sense of linked data. Search engines would read the title and never understand that these pages refer to items that are a part of creative work collections.
Anatomical Figure of a Horse (ecorche), part of Torrie Collection (before)
Keeping this in mind we started mapping the schema specification in the record files of the website. There were certain fields such as ‘Inscriptions’ and ‘Provenance’ that could not be mapped because Schema does not support a specification for them yet. We are documenting all such findings and plan to make suggestions to Schema.org regarding the same.
Implementation of mapping in the configuration file of Art collections
This was followed by implementing changes directly in the record files of the collection. There were a lot of challenges such as marking up images, videos and audios. Especially from images point of view, some websites used the IIIF format and others used the bitstream which required making wise decisions in how to mark up such websites. With a lot of help and guidance from Scott we were able to resolve these issues and the end result of the efforts was absolutely rewarding.
After: Using the CreativeWorks class of Schema the websites have been marked up. Now, search engines can see that these items refer to creative work category such as art, sculpture, instrument etc. They are rich in other details such as name of creator, name of collection, description etc. These huge changes are bound to increase the discoverability of collections website.
Anatomical Figure of a Horse (ecorche), part of Torrie Collection (after)
I was very fortunate that Google Analytics and Search Engine Optimisation (SEO) trainings were held at the Argyle House during my internship period and I was able to get insights from these trainings. They illuminated a whole new direction and lend a different viewpoint. The SEO workshops in particular gave ideas about optimizing the overall content of the websites and making St.Cecilias more discoverable. I realized the benefits of SEO are seen in the form of increased traffic, Return on Investment (ROI), cost effectiveness, increased site usability and brand awareness. These tools combined with schema can add significant value to the library services everywhere. It is a feeling of immense pride that our university is among the very few universities that have employed schema for their collections. We are confident that schema will make the collections more accessible not only to students but also to the people worldwide who want to discover the jewels held in these collections. The 13 collections website that we worked on during our internship are nearing completion from implementation perspective and will be live soon with Schema markup.
To conclude, my internship has been an amazing experience, both in terms of meaningful strides in the direction of marking up the collections website and the fun, conducive work-culture. Having never worked on the web development side before, I got the opportunity to understand first-hand the intricacies associated in anticipating the needs of users and delivering a perfect information-rich website experience to the users. As the project culminates in July, I am happy to have learned and contributed much more than I imagined I would in the course of my internship.
Nandini Tyagi (Library Digital Development)
Thanks very much to both Nandini and Holly on their sterling work on this project. We’ve implemented schema in 3 sites already (look at https://collections.ed.ac.uk/art for an example), and we have another 6 in github ready to be released. The interns covered a wealth of data, and we think we’re in a position to advise 1) LTW that this material can now be better used in the University website’s search and 2) prospective developers on how to apply this concept to their sites.
This blog was written by Holly Coulson, who is working with Nandini Tyagi on this project.
For the last three months, I have been undergoing a Library Metadata internship with the Digital Development team over in Argyle House. Having the opportunity to see behind the scenes into the more technical side of the library, I gained far more programming experience I ever imagined I would, and worked hands on with the collections websites themselves.
Most people’s access to University of Edinburgh’s holdings is primarily through DiscoverEd. But the Collections websites exist as a complete archive of all of the materials that Edinburgh University have, from historical alumni to part of the St Cecilia’s Hall musical instrument collection. These sites are currently going through an upgrade, with new interfaces and front pages.
My role in all of this, along with my fellow intern Nandini, was to analyse and improve how the behind-the-scenes metadata works in the grander scheme of things. As the technological world continually moves towards linked data and the interconnectivity of the Internet, developers are consciously having to update their websites to include more structured data and mark-up. That was our job.
Our primary aim was to implement Schema.org into the collections.ed.ac.uk spaces. Schema, an open access structured data vocabulary, allows for major search engines, such as Google and Yahoo to pull data and understand what it represents. For collections, you can label the title as a ‘schema:name’ and even individual ID numbers as ‘schema:Identifier’. This allows for far more reliable searching, and allows websites to work in conjunction with a standardised system that can be parsed by search engines. This is ultimately with the aim to optimise searches, both in the ed.ac.uk domain, and the larger search engines.
Our first major task was the research. As two interns, both doing our Masters, we had never heard of Schema.org, let alone seen it implemented. We analysed various collections sites around the world, and saw their use of Schema was minimal. Even large sites, such as the Louvre, or the National Gallery, didn’t include any schema within their record pages.
With minimal examples to go off, we decided to just start mapping our metadata inputs to the schema vocabulary, to get a handle on how Schema.org worked in relation to collections. There were some ideas that were very basic, such as title, author, and date. The basics of meta-data was relatively easy to map, and this allowed us to quickly work through the 11 sites that we were focusing on. There were, however, more challenging aspects to the mapping process, which took far longer to figure out. Schema is rather limited for its specific collection framework. While bib.schema exists, an extension that specifically exists for bibliographic information, there is little scope for more specific collection parameters. There were many debates on whether ‘bib.Collection’ or ‘isPartOf’ worked better for describing a collection, and if it was viable to have 4 separate ‘description’ fields, for different variations of abstracts, item descriptions, and other general information.
The initial mappings for /art, showing relatively logical and simple fieldsMore complicated mappings in /stcecilias, with a lot of repetition and similar fields, and ones that were simply not possible, or weren’t required.
There were other, more specific, fields we had to deal with, that threw up particular problems. The ‘dimensions’ field is always a combined height and width. Schema.org, with regards to specific dimensions, only deals with individual values: a separate height and a separate width value. It wasn’t until we’d mapped everything that we realised this, and had to rethink our mapping. There was also many considerations for if Schema.org was actually required for every piece of metadata. Would linking specific cataloguing and preservation descriptions actually be useful? How often would users actually search for these items? Would using schema.org actually help these fields? We continually had to consider how users actually searched and explored the websites, and whether adding the schema would aid search results. By using a sample of Google Analytics data, we were able to narrow down what should actually be included in the mapping. We ended up with 11 tables, for 11 websites (see above), offering a precise mapping that we could implement straight away.
The next stage was figuring out how to build the schema into the record pages themselves. Much of the Collections website is run on PHP, which takes the information directly from the metadata files and places them in a table when you click on an individual item. Schema.org, in its simplest form, is in HTML, but it would be impossible to go through every single record manually and mark it up. Instead, we had to work with the record configuration files to allow for variables to be tested for schema. If they were a field with a schema definition, the schema.org tag is printed around it, as an automated process. This was further complicated by filters that are used, meaning several sets of code were often required to formulate all the information on the page. As someone who had never worked with PHP before, it was definitely a learning curve. Aided by various courses on search engine optimisation and Google Analytics, we were becoming increasingly confident in our work.
Our first successes were uploading both the /art and /mimed collections schema onto the test servers, only receiving two minimal errors. This proved that our code worked, and that we were returning positive results. By using a handy plugin in Chrome, we were able to see if the code was actually offering readable Schema.org that linked all of our data together.
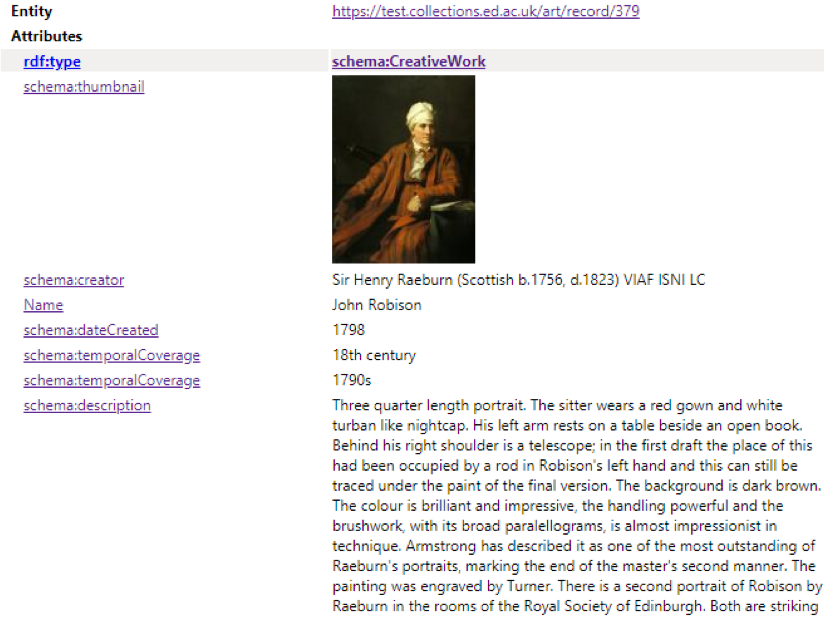
The plugin, OpenLink Structured Data Sniffer, showing the schema and details attributed to the individual record. In this case, Sir Henry Raeburn’s painting of John Robison.
As we come to the final few weeks of our internship, we’ve learnt far more about linked data and search engine optimisation than we imagined. Being able to directly work with the collections websites gave us a greater understanding of how the library works overall. I am personally in the MSc Book History and Material Culture programme, a very hands-on, physical programme, and exploring the technical and digital side of collections has been an amazingly rewarding experience that has aided my studies. Some of our schema.org coding will be rolled out to go live before we finish, and we have realised the possibilities that structured data can bring to library services. We hope we have allowed one more person to find the artwork or musical instrument they were looking for. While time will tell how effective schema.org is in the search results pages, we are confident that we have helped the collections become even more accessible and searchable.
We (Joe Marshall (Head of Special Collections) and Scott Renton (Library Digital Development)) visited Washington DC for the IIIF Conference from 21st-25th May. This was a great opportunity for L&UC, not only to visit the Library of Congress- the mecca of our industry in some ways- but also to come back with a wealth of knowledge which we could use to inform how we operate.
From a purely practical level, it was great to meet face to face with colleagues from across the world- we have a very real example of a problem solved with Drake from LUNA, which we hope to be able to show very soon. It was also interesting to see how the API specs are developing- the presentation API will be enhanced with AV in version 3, and we can already see some use cases with which to try this out; search and discovery are APIs we’ve done nothing with, but these will help the ability to search within and across items, which is essential to our estate of systems, and 3D, while not having an API of its own, is also being addressed by IIIF, and it was fascinating to see the work that Universal Viewer and Sketchfab (which the DIU use) are doing to accommodate it.
The community groups are growing too, and we hope to increase our involvement with some of the less technical areas- Manuscripts, Museums, and the newly-proposed Archives group in the near future.
Among a wealth of great presentations, we’ve each identified one as our favourite:
This fascinating talk highlighted IIIF’s ability to work out which parts of an image, when zoomed in, are most popular. Often this is done by installing special tools such as eyetrackers, but the nature of IIIF- where the region is displayed as part of the URL- the same information can be visualised by interrogating Apache access logs. Chifumi and Kiyonori have been able to generate heatmaps of the most interesting regions on an item, and the code can be re-used if the logs can be supplied.
This talk showed the potential of IIIF in the context of digital preservation, providing large-scale public access to born-digital archive records without having to create exhaustive item-level metadata. The IIIF world is encouraging this kind of blue-sky thinking which is going to challenge many of our traditional professional assumptions and allow us to be more creative with collections projects.
It was a terrific trip, which has filled us with enthusiasm for pushing on with IIIF beyond its already significant place in our set-up.
Joe Marshall & Scott Renton Library Of Congress Exhibition
The main portal into Library and University Collections’ Special Collections content, collections.ed.ac.uk, is changing. A design overhaul which will improve discovery both logically and aesthetically is coming very soon, but in advance, we’ve implemented an important element of functionality, namely the IIIF approach to images.
Two sites have been affected to that end: Art (https://collections.ed.ac.uk/art– 2859 IIIF images in 2433 manifests across 4715 items) and Musical Instruments (https://collections.ed.ac.uk/mimed– 8070 IIIF images in 4097 manifests across 5105 items)) now feature direct IIIF thumbnails, embedded image zooming and manifest availability. A third site, the St Cecilia’s Hall collection (https://collections.ed.ac.uk/stcecilias) already had the first two elements, but manifests for its items are now available to the user.
What does this all mean? To take each element in turn:
Direct IIIF thumbnails
The search results pages on the site no longer directly reference images on the collections.ed servers, but bring in a LUNA URL using the IIIF image API format, which offers the user flexibility on size, region, rotation and quality.
Embedded image zooming
Using IIIF images served from the LUNA server and the OpenSeadragon viewer, images can now be zoomed directly on the page, where previously we needed an additional link out to the LUNA repository.
Manifest availability
Based on the images attached to the record in the Vernon CMS, we have built IIIF manifests and made them available, one per object. Manifests are a set of presentation instructions to render a set of images according to curatorial choice, and they can be dropped into standard IIIF viewers. We have created a button to present them in Universal Viewer (UV), and will be adding another to bring in Mirador in due course.
Watch this space for more development on these sites in the very near future. The look-and-feel will change significantly, but the task will be made easier with IIIF as a foundation.
Never waste a football-related pun. It’s been a good week for both PSV and CSV.
I was lucky enough to have a paper accepted to Csv,conf,2* in Berlin on the 3rd-4th of May, which was great to do, but it also got me through the door to see loads of great things going on in data and its surrounding technology. Yes, there was heavy mention made of CSV and Spreadsheets; in fact, at times it was akin to an AA meeting ,with people guiltily admitting their love of Excel. This left me feeling- quite worryingly- vindicated in a lot of the things I do.
As is always the case with any conference review blogpost, it’s not viable to list every link or ruminate on the message of every talk, so I’ll just home in on a few highlights. The talks (available in slide or video form) are appearing over at Lanyrd.com, and they’ll give a lot more depth to what was spoken about.
My own reason for being there- as far as my talk was concerned- was to look at better ways of processing workflow, enriching data, and improving engagement with our collections. Afterwards, I had some interesting conversations: I was alerted to the tool NeuralTalk2 by Maciej Gryka of rainforestqa.com, a company that specialises in cleaning data using mechanical turks and crowdsourced test-cases. Neural Talk, though, is a captioning tool, which will attempt to visually recognise what your image is “of”. I’m sure it fails as much as it succeeds, but, as I pointed out, we’ve not really used this kind of tech to enhance our metadata, so there’d be no harm in running some of our images through and seeing what it comes up with. Another chat, with a lady from UC Santa Cruz, made it clear that we are quite liberal with our approach to crowdsourced data. Where we have generally decided it’s fine to surface as long as it is properly marked as such, they are proceeding rather slowly, due to a particularly strict metadata librarian.
The keynotes were deliberately intended to cover a range of disciplines that might be new to most people at this highly eclectic conference. Resultantly, there were interesting talks on technology and activism (including visualisations of the Ebola crisis and police brutality); ethics in technology and workflows to give your consent without clicking on unreadable terms and conditions (do you know what SmartBins are taking from you as you pass?); dealing with messy spreadsheets (the Enron crisis showed this institution to manage them terribly), and open data with neuroscience (a lot of mouse brains in action).
Some other tools that we could be looking at:
Zegami – great for exploring large banks of images and spotting patterns across them. Can it work with IIIF, I wonder?
OpenRefine– a tool that we perhaps should have been using for some time to rationalise spreadsheet data, which could certainly save lots of time. Our former colleague, Richard Jones of cottagelabs, is a great advocate of these kinds of tools, as his talk made clear.
DataBaker– created in collaboration between the Office of National Statistics and ScraperWiki. This Python application can convert any ‘pretty’ spreadsheet into usable source data in CSV.
CSV Rinse and Repeat– built in Paris by Mathieu Jacomy of the Paris MediaLab, this is a JavaScript tool which intends to cut down the distance between data, coding and visualisation. Basically you take your data, spot patterns, recode to surface interesting things, and generate a visualisation out the end, in an iterative process.
Wikipedia Googlesheets– I am not sure if we would have a use for this specifically, but it was fascinating to see a plugin which serves up spreadsheet formulae coded in Google Apps JavaScript, which can then be used to interrogate any Wikipedia pages. Particularly of note is the ability to combine category pages and pageviews, to see if real-time events are influenced by Wikipedia and vice-versa. Developed by Thomas Steiner at Google.
Finally, here are three interesting observations, which certainly struck a chord with me:
It is now deemed quite acceptable, as a symptom of rapid development, perhaps, that the CSV is used as the master dataset; perhaps the file-based database’s day is not over. I certainly found out about some interesting applications built in this way.
I heard no-one but myself talk about Excel macros- at a spreadsheet conference, no less! It is far more fashionable these days to read your data as csv, and code against it using JavaScript, R, or Python. I clearly need to get out of the 1990s.
EVERYONE suffers from problems with diacritics, glyphs, badly formatted data and what happens when you import a CSV into a spreadsheet tool that tries to be too clever. It is not just me.
All in all, an excellent couple of days, which have filled me with ideas for improvements for existing workflows. Hopefully the likes of the DIU will reap some benefits!
Insert standard caption regarding “old content meets new technology to surface it”!
Quick caveat: this post is a partner to the one Claire Knowles has written about our signing up to the IIIF Consortium, so the explanation of the acronym will not be explained here!
The Library Digital Development team decided to investigate the standard due to its appearance at every Cultural Heritage-related conference we’d attended in 2015, and we thought it would be apposite to update everyone with our progress.
First things first: we have managed to make some progress on displaying IIIF formatting to show what it does. Essentially, the standard allows us to display a remotely-served image on a web page, with our choice of size, rotation, mirroring and cropped section without needing to write CSS, HTML, or use Photoshop to manipulate the image; everything is done through the URL. The Digilib IIIF Server was very simple to get up and running (for those that are interested, it is distributed as a Java webapp that runs under Apache Tomcat), so here it is in action, using the standard IIIF URI syntax of [http://[server domain]/[webapp location]/[specific image identifier]/[region]/[size]/[mirror][rotation]/[quality].[format]]!
The URL for the following (image 0070025c.jpg/jp2) would be:
[domain]/0070025/full/full/0/default.jpg
This URL is saying, “give me image 0070025 (in this case an Art Collection poster), at full resolution, uncropped, unmirrored and unrotated: the standard image”.
This URL says, “give me the same image, but this time show me co-ordinates 300px in from the left, 50 down from the top, to 350 in from the left, to 200 down from the top (of the original); return it at a resolution of 200px x 200px, rotate it at an angle of 236 degrees, and mirror it”.
The server software is only one part of the IIIF Image API: the viewer is very important too. There are a number of different viewers around which will serve up high-resolution zooming of IIIF images, and we tried integrating OpenSeaDragon with our Iconics collection to see how it could look when everything is up and running (this is not actually using IIIF interaction at this time, rather Microsoft DeepZoom surrogates, but it shows our intention). We cannot show you the test site, unfortunately, but our plan is that all our collections.ed.ac.uk sites, such as Art and Mimed, which have a link to the LUNA image platform, can have that replaced with an embedded high-res image like this. At that point, we will be able to hide the LUNA collection from the main site, thus saving us from having to maintain metadata in two places.
We have also met, as Claire says, the National Library’s technical department to see how they are doing with IIIF. They have implemented rather a lot using Klokan’s IIIFServer and we have investigated using this, with its integrated viewer on both Windows and Docker. We have only done this locally, so cannot show it here, but it is even easier to set up and configure than Digilib. Here’s a screenshot, to show we’re not lying.
Our plan to implement the IIIF Image API involves LUNA though. We already pay them for support and have a good working relationship with them. They are introducing IIIF in their next release so we intend to use that as a IIIF Server. It makes sense- we use LUNA for all our image management, it saves us having to build new systems, and because the software generates JP2K zoomable images, we don’t need to buy anything to do that (this process is not open, no matter how Open Source the main IIIF software may be!). We expect this to be available in the next month or so, and the above investigation has been really useful, as the experience with other servers will allow us to push back to LUNA to say “we think you need to implement this!”. Here’s a quick prospective screenshot of how to pick up a IIIF URL from the LUNA interface.
We still need to investigate more viewers (for practical use) and servers (for investigation), and we need to find out more about the Presentation API, annotations etc., but we feel we are making good progress nonetheless.
The overwhelming setting of the British Museum played host to this year’s Museums Computer Group “Museums and the Web” Conference, and as usual, a big turnout from museums institutions all over the UK came, bursting with ideas and enthusiasm. The theme (“Bridging Gaps and Making Connections”) was intended to encourage thought about identifying creative spaces between physical museums collections and digital developments, where such spaces are perhaps too big, and how they can be exploited. As usual, there was far too much interesting content to cover fully in a blogpost- everything was thought-provoking, but I’ve picked out a few highlights.
Two projects highlighted collaboration between museums, which can be creatively explosive, and immediately improve engagement. Russell Dornan at The Wellcome Institute showed us #MuseumInstaSwap, where museums paired off and filled their social media feeds with the other museum’s content. Raphael Chanay at MuseoMix, meanwhile, arguably took this a step further by getting multiple institutions to bring their objects to a neutral location (Iron Bridge in Shropshire, Derby Silk Mill), and forming teams to build creative prototypes out of them across the digital and physical spaces. Could our museums collections be exploited in similar ways? Who could we partner up with?
I like to think that our “digital and physical” teams in L&UC collaborate very effectively. Keynote speaker John Coburn from TWAM (Tyne and Wear Archives and Museums) spoke of the importance of this intra-institution collaboration. You will (almost) never find a project that is run entirely from within the digital or physical sphere (Fiona Talbott from the HLF confirmed this- 510 of 512 recent bids had digital outputs relating to physical content), and the ability of the digital area and the content providers to communicate and work together is key. One very good example of this was the Tributaries app, built with sound artists, the history team, archives and so on, to put together an immersive audio experience of lost Tyneside voices from World War I. He also spoke of their TNT (Try New Things) initiative (also creatively explosive!) where staff sign up to do innovation with the collections, effectively in their spare time. With the Innovation Fund encouraging creativity, how do we work this into our daily lives? Can we? If not, how do we incentivise people to do it outwith their spare time? One of the gloomier observations of the day was that, with austerity, there is less and less money in the sector, which is likely to get worse after next month’s spending review. This austerity can breed creativity, though, and it’s good for digital, because people need to ‘work smarter’.
Another really interesting project is going on at the Tate, where they are combining their content with the Khan Academy learning platform. Rebecca Sinker and colleagues showed us how content can be levered and resurrected through a series of video tutorials around the content (be they archival, technical, biographical etc). Pushing the collaborative textual content from the comments area on the tutorials through to social media allows further engagement and new perspectives on the museum objects. Speaking personally, I have had little exposure to our VLE, but I’m quite sure that developing an interface between it and our collections sites could be highly beneficial.
That’s all the tip of the iceberg, though, so take a look at the programme link at the top to find out about lots of other interesting projects.
Outside of the lecture theatre, I had some really interesting conversations with people who have exactly the same problems as ourselves: building image management workflows, incorporating technological enhancements to content-driven websites, and thinking about beacon technology (the sponsors, Beacontent, deserver top marks for the name at least). Additionally, a tour of The Samsung Digital Discovery Centre– where state of the art technology meets British Museum content to improve the experience for children, teenagers, and families- was highly informative.
The Towards Dolly project, showcasing research from genetics at the Roslin Institute, has helped surface lots of interesting material within the library, not least at the current exhibition. One of its outputs was the Science On A Plate subproject, a Wellcome-funded digitisation of 3,500 glass plate slides.
We’ve put these into our metadata games infrastructure, to allow social tagging of the slides, and- while they are well-described- improve their keywording to allow superior faceting in the LUNA application, making the collection more searchable. The game follows the same methodology as the Tag It! Find It! art game- tag ten images, and vote on ten, and build up a high score. It has the additional incentive though, of a hidden Dolly The Sheep image. The lucky user who comes across this image first will be lavishly rewarded (i.e. they will almost certainly get an L&UC calendar!)!!
The game was launched in time for a talk given by Gavin Willshaw, Clare Button and Claire Knowles at The Central Library– a great example of our Library engaging with the wider community- on Tuesday September 29, and will be featured again at Ada Lovelace Day on October 13. You don’t need to be at these events to play the game though- it’s there for you to have a go at any time you like, at librarylabs.ed.ac.uk. You’ll need to login via EASE.
While our main contribution to the Europeana Tech revolved around the metadata games on this site, there was a veritable feast of things for us to consider for our future work.
In no particular order, I’d just like to say a little bit about the best of them, to focus us on where we could be improving processes.
Image strategy in general. It pains me to say this, as such a large proportion of my work in this job has been with the LUNA imaging system, but I can see the way the wind is blowing, and it would be churlish not to acknowledge it. The IIIF– International Image Interoperability Framework is increasingly becoming the standard for open sharing and hosting of images. With a host of open source tools for storage and discovery, such as OpenSeaDragon, which zooms at least as well as LUNA does, we could be looking at options to have all of our collections in one application, instead of linking out. We could be sharing images to other tools without having to store so many derivatives. We would be in a position of confidence that everything is being done to a standard. It’s still in its infancy, but the Bodleian- who used to use LUNA- have moved over, and the National Library of Wales are using it too.
APIs for data. The Europeana APIs are there for our use, to let developers from contributing institutions just get in and build stuff. We could be employing this to pick up metadata for our LUNA images as an alternative to the LUNA API (which we will need to use when the database goes in v7), and thus could employ it in our Flickr API, our metadata games, and our Google Analytics API. More than that, though, with a small tweak, we could be pointing metadata games to the WHOLE of Europeana, thus allowing us to do a service to other institutions- getting their data enriched, and supplying them with crowdsourced information. This would be great for our profile.
Using Linked Open Data. This comes up again and again, and would definitely come into play if we were to build an authorities repository. Architecturally, the approach is likely to involve RDF, although cataloguing can be done through CIDOC-CRM, from which RDF can be extracted. CIDOC-CRM is looking to have an extension for SPECTRUM, which Vernon uses, so there could be some interesting changes to how Vernon looks in the years ahead.
Alternatives to searching. One of the messages that rang out loud and clear at the conference is that people do not go to a museum to DO A SEARCH. Ways of presenting data without a search button as such are being looked at, and some sites which do this are here: V&A Spelunker Serendipomatic Netflixomatic
One other thing that occurred to me, thanks to Seb Chan at Cooper Hewitt, in relation to our work for St Cecilia’s- videos which show objects in the round, 3-D versions. Is it enough to show a flat image, or a bit of audio, for something that is in a display case?
In the tradition of Library Labs, this is a bit of a brain dump, and I will inevitably think of more content for this post over the next few days. It’s a start though!








 The main portal into Library and University Collections’ Special Collections content, collections.ed.ac.uk, is changing. A design overhaul which will improve discovery both logically and aesthetically is coming very soon, but in advance, we’ve implemented an important element of functionality, namely the IIIF approach to images.
The main portal into Library and University Collections’ Special Collections content, collections.ed.ac.uk, is changing. A design overhaul which will improve discovery both logically and aesthetically is coming very soon, but in advance, we’ve implemented an important element of functionality, namely the IIIF approach to images.













