This blog was written by Holly Coulson, who is working with Nandini Tyagi on this project.
For the last three months, I have been undergoing a Library Metadata internship with the Digital Development team over in Argyle House. Having the opportunity to see behind the scenes into the more technical side of the library, I gained far more programming experience I ever imagined I would, and worked hands on with the collections websites themselves.
Most people’s access to University of Edinburgh’s holdings is primarily through DiscoverEd. But the Collections websites exist as a complete archive of all of the materials that Edinburgh University have, from historical alumni to part of the St Cecilia’s Hall musical instrument collection. These sites are currently going through an upgrade, with new interfaces and front pages.
My role in all of this, along with my fellow intern Nandini, was to analyse and improve how the behind-the-scenes metadata works in the grander scheme of things. As the technological world continually moves towards linked data and the interconnectivity of the Internet, developers are consciously having to update their websites to include more structured data and mark-up. That was our job.
Our primary aim was to implement Schema.org into the collections.ed.ac.uk spaces. Schema, an open access structured data vocabulary, allows for major search engines, such as Google and Yahoo to pull data and understand what it represents. For collections, you can label the title as a ‘schema:name’ and even individual ID numbers as ‘schema:Identifier’. This allows for far more reliable searching, and allows websites to work in conjunction with a standardised system that can be parsed by search engines. This is ultimately with the aim to optimise searches, both in the ed.ac.uk domain, and the larger search engines.
Our first major task was the research. As two interns, both doing our Masters, we had never heard of Schema.org, let alone seen it implemented. We analysed various collections sites around the world, and saw their use of Schema was minimal. Even large sites, such as the Louvre, or the National Gallery, didn’t include any schema within their record pages.
With minimal examples to go off, we decided to just start mapping our metadata inputs to the schema vocabulary, to get a handle on how Schema.org worked in relation to collections. There were some ideas that were very basic, such as title, author, and date. The basics of meta-data was relatively easy to map, and this allowed us to quickly work through the 11 sites that we were focusing on. There were, however, more challenging aspects to the mapping process, which took far longer to figure out. Schema is rather limited for its specific collection framework. While bib.schema exists, an extension that specifically exists for bibliographic information, there is little scope for more specific collection parameters. There were many debates on whether ‘bib.Collection’ or ‘isPartOf’ worked better for describing a collection, and if it was viable to have 4 separate ‘description’ fields, for different variations of abstracts, item descriptions, and other general information.


There were other, more specific, fields we had to deal with, that threw up particular problems. The ‘dimensions’ field is always a combined height and width. Schema.org, with regards to specific dimensions, only deals with individual values: a separate height and a separate width value. It wasn’t until we’d mapped everything that we realised this, and had to rethink our mapping. There was also many considerations for if Schema.org was actually required for every piece of metadata. Would linking specific cataloguing and preservation descriptions actually be useful? How often would users actually search for these items? Would using schema.org actually help these fields? We continually had to consider how users actually searched and explored the websites, and whether adding the schema would aid search results. By using a sample of Google Analytics data, we were able to narrow down what should actually be included in the mapping. We ended up with 11 tables, for 11 websites (see above), offering a precise mapping that we could implement straight away.
The next stage was figuring out how to build the schema into the record pages themselves. Much of the Collections website is run on PHP, which takes the information directly from the metadata files and places them in a table when you click on an individual item. Schema.org, in its simplest form, is in HTML, but it would be impossible to go through every single record manually and mark it up. Instead, we had to work with the record configuration files to allow for variables to be tested for schema. If they were a field with a schema definition, the schema.org tag is printed around it, as an automated process. This was further complicated by filters that are used, meaning several sets of code were often required to formulate all the information on the page. As someone who had never worked with PHP before, it was definitely a learning curve. Aided by various courses on search engine optimisation and Google Analytics, we were becoming increasingly confident in our work.
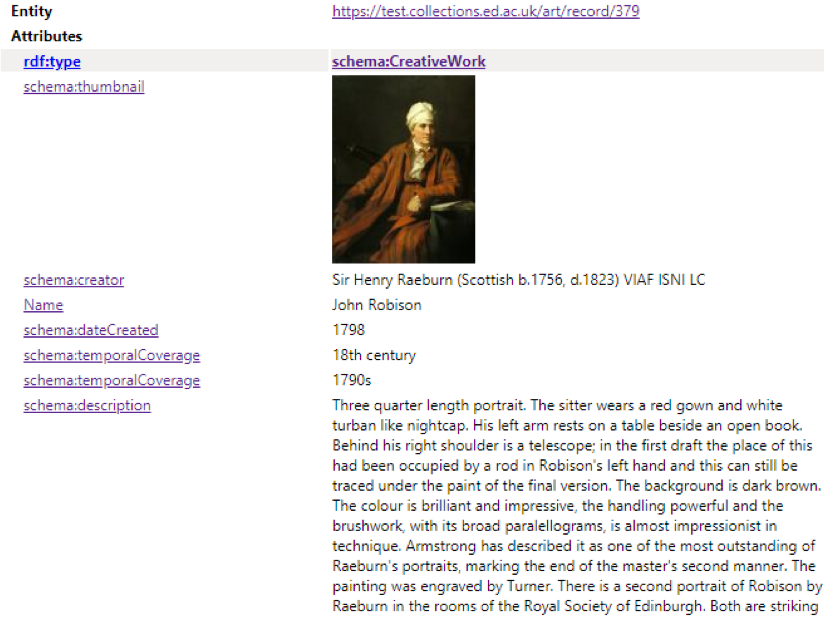
Our first successes were uploading both the /art and /mimed collections schema onto the test servers, only receiving two minimal errors. This proved that our code worked, and that we were returning positive results. By using a handy plugin in Chrome, we were able to see if the code was actually offering readable Schema.org that linked all of our data together.
As we come to the final few weeks of our internship, we’ve learnt far more about linked data and search engine optimisation than we imagined. Being able to directly work with the collections websites gave us a greater understanding of how the library works overall. I am personally in the MSc Book History and Material Culture programme, a very hands-on, physical programme, and exploring the technical and digital side of collections has been an amazingly rewarding experience that has aided my studies. Some of our schema.org coding will be rolled out to go live before we finish, and we have realised the possibilities that structured data can bring to library services. We hope we have allowed one more person to find the artwork or musical instrument they were looking for. While time will tell how effective schema.org is in the search results pages, we are confident that we have helped the collections become even more accessible and searchable.
Holly Coulson (Library Digital Development)

