Home University of Edinburgh Library Essentials
April 20, 2024

Digital Humanities Oxford Summer School – days 1 and 2
Posted on July 21, 2015 | in Research & Learning Services | by Gavin Willshaw
I’m down in Oxford this week for the Digital Humanities Oxford Summer School (DHOxSS), a five-day festival of digital scholarship showcasing the latest developments in research in the field and providing tools, guidance and advice on strategies for managing and using humanities data. I’ve signed up for the Digital Approaches in Medieval and Renaissance Studies (“the technologies of the present enhancing the study of the past”) which, throughout the week, focuses on topics ranging from ‘DIY digitisation’ and multispectral imaging, through to TEI, the Semantic Web, IIIF and social media as ‘social machines’. I plan to write up my full notes from the week once I’m back, but here is a small list of observations and useful links from days 1 and 2:
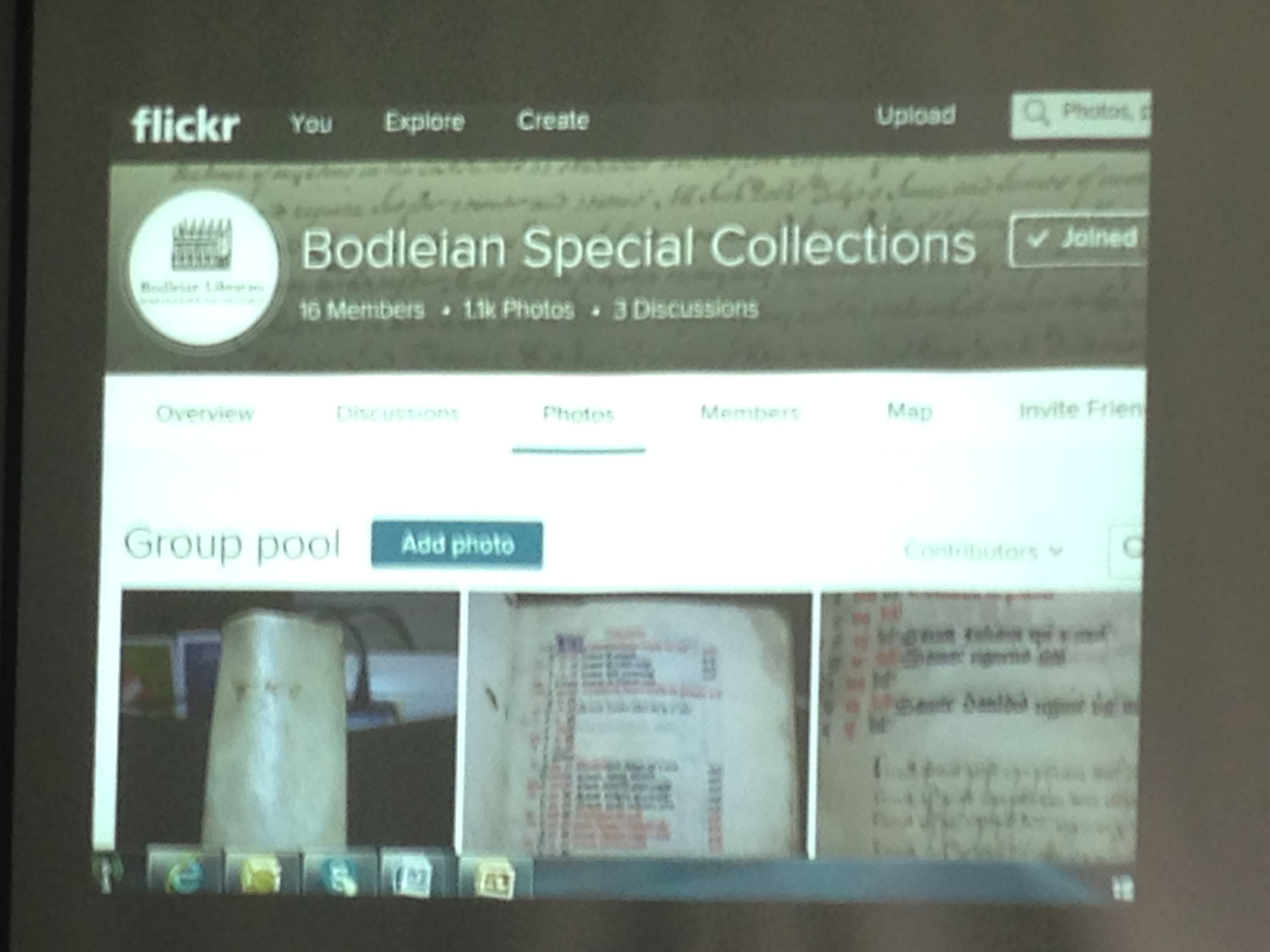
– ‘DIY digitisation’ is an excellent way for researchers to undertake their own small scale and low cost digitisation projects. The Bodleian encourages DIY digitisers to share their images on Flickr flickr.com/groups/bodspecialcollections, thereby encouraging discussion and debate and enabling the library to capture information about items its users want to see in digital format.
– Retroreveal http://retroreveal.org/ is a highly-recommended tool for uncovering what lies beneath the surface of digital images. It transforms images from the RGB colourspace perceived by the naked eye into other colourspaces, thereby revealing hidden text, annotations and images within digital files.
– The Walters Art Museum http://www.thedigitalwalters.org/ has been highlighted as something of a holy grail for digital humanities scholars: the entire collection is available on a CC-BY-SA licence in a variety of sizes and resolutions, right up to the 1200 dpi master TIFFs.
– There was an interesting discussion around the ethics of ‘DIY digitisation’ centered on what users should be allowed to do with images digitised in this way. One example was of the twitter account Medieval Reactions https://twitter.com/medievalreacts create humorous images / which tweets humorous, often offensive, memes using digitised images from rare books, and generates income from hosting promoted tweets. Should libraries be funding private income generation in this way?
– The Bodleian is doing fascinating work on hyperspectral imaging http://www.bodleian.ox.ac.uk/news/2014/sep-16, enabling researchers to see hidden texts within images and analyse materials in a new way. In the image below, a stamp on the Gettsyburg Address not visible to the human eye can be seen when viewed within the VNIR and SWI spectral range. Hyperspectral images create huge file sizes (30GB+) and require complex data processing but can reveal secrets in documents which have never been uncovered before.

– OCR does an excellent job for printed, standardised documents but is not able to replicate the original structure of a document and it presents all text in a uniform size and font, even though it may not appear like this in the original document. As well as this, text can only be processed when it runs horizontally and faint items are not picked up well. The EMOP project http://emop.tamu.edu/ is an interesting tool which utilises crowdsourcing and other techniques to overcome some of these issues.
– Oxford museums have been experimenting with using the basal metabolic rate emitted by all smart phones to track and record (anonymously!) their visitors’ movements throughout the museum space; this approach is an interesting one which I had not come across before. The aim is to deliver relevant content to visitors along the lines of Amazon’s “maybe you’d like…” service, based on their viewing habits within the museum space.
– Image recognition technology has been used in the Bodleian Broadsides project to identify wood blocks used by printers, shedding new light on the location and activities of printers across Europe in the early modern period http://imagematch.bodleian.ox.ac.uk:8000/page0. Image recogntion technology such as this could have profound implications for all institutions with a large backlog of poorly-described digital images.

The above is just a small snapshot of what I’ve learned so far from the Summer School. I’m not even halfway through yet, so there’ll be plenty more to come from me over the next few days!
Collections
 Archival Provenance Project: a glimpse into the university’s history through some of its oldest manuscripts
My name is Madeleine Reynolds, a fourth year PhD candidate in History of Art....
Archival Provenance Project: a glimpse into the university’s history through some of its oldest manuscripts
My name is Madeleine Reynolds, a fourth year PhD candidate in History of Art....
 Rediscovering the Poetry of Louisa Agnes Czarnecki, a 19th-Century Edinburgh Writer and Musician
Today we are publishing a blog by Ash Mowat, a volunteer in the Civic Engagement...
Rediscovering the Poetry of Louisa Agnes Czarnecki, a 19th-Century Edinburgh Writer and Musician
Today we are publishing a blog by Ash Mowat, a volunteer in the Civic Engagement...

Projects
Giving Decorated Paper a Home … Rehousing Books and Paper Bindings
In the first post of this two part series, our Collection Care Technician, Robyn Rogers,...
The Book Surgery Part 2: Bringing Everything Together
In this blog, Project Conservator Mhairi Boyle her second day of in-situ book conservation training...